



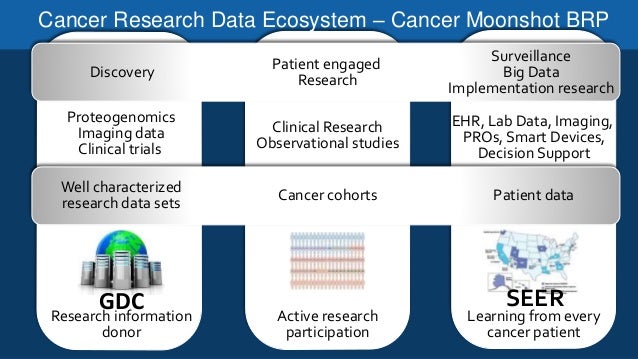
Data is ubiquitous in Gesundheitswesen—from hospitals, laboratories and Forschung centres to surveillance systems, data makes up an indiscriminate part of healthcare systems. In fact, there is a myriad of types of data in biosciences research collected through clinical research or generated by genome sequencing or computational drug modelling. Krebsforschung in particular benefits from the applications of big data and analytics. Cancer screening programs initiate rich repertoires of imaging and laboratory data, which require in-depth analysis and repeated testing in order for real value to be derived from it. Repeated testing and Datenanalyse enable clinical researchers to develop better drugs, understand their attributes in vivo und neuartige Medikamente zur Krebsbekämpfung herstellen.
Es ist kein Geheimnis, dass große Daten gilt als die sichere Methode, um die Komplexität von Krebs zu durchbrechen. Es besteht der Drang, neue Mechanismen zur Behandlung von Krebs zu entwickeln, was die Unternehmen dazu veranlasst hat, Tools zur Datenvisualisierung/-analyse zu untersuchen. Das Erfassen, Sammeln, Speichern und Analysieren von Daten aus Krebszellen ist ein ganz neues Spiel, bei dem Wohlwollende KI, 10X Genomik, Insilico-Medizin und NuMedii haben ihre ersten Meilensteine erreicht. In fact, 10X Genomics has gone the extra mile to provide whole genome sequencing, exome sequencing and single cell transcriptome analysis services that vividly indicate cancer-prone gene sequences in the DNA, mRNA and polypeptide chains, respectively. Few others are utilizing broader data frameworks, novel screening mechanisms and high definition data filtering algorithms to test cancer drugs on a wide range of cellular environments.
Die Anwendbarkeit von Big Data in der Krebsdiagnose, -erprobung und -verwaltung wird als entscheidender Schritt auf dem Weg zu einer Krebsforschung der nächsten Generation gepriesen. Hier sind 7 Möglichkeiten, wie sich Big Data auf die Krebsforschung auswirkt.
1. Sequenzierung der Krebsgenome des Menschen

Jede Zelle unseres Körpers hat die gleiche Anzahl von Chromosomen und etwa das gleiche Volumen an DNA. Krebszellen weisen jedoch deutliche Abweichungen in Bezug auf den Chromosomeninhalt und das Wachstum auf, die, wenn sie einer In-silico-Visualisierung unterzogen werden, genutzt werden können, um Informationen bis hinunter auf die DNA-Ebene zu erschließen. Diese Sequenzierungsstudien können Zellbiologen, Bioinformatikern, Molekularbiologen und Nanobiotechnologen dabei helfen, bessere Methoden zur Beseitigung chromosomaler Anomalien zu entwickeln, die zu möglichen therapeutischen Wegen führen können.
2. Hochdurchsatz-Sequenzierung von Patientenproben
Wir leben in einer Zeit, in der die personalisierte Medizin in der Gesundheitsversorgung alltäglich wird, und Krebs ist der größte Anwendungsbereich für diesen Fortschritt. Dieser Vorstoß in Richtung personalisierte Medizin hat die Computerbiologie in den Mittelpunkt gerückt, den Zweig der Biologie, der die Gesundheitsversorgung so anspruchsvoll macht, wie sie heute gesehen wird. Professor Olivier Elementoein Experte für Computermedizin an der Cornell University, betont, dass sich Krebszellen ständig verändern, weiterentwickeln und sich an die menschliche Umgebung anpassen, so dass schnellere Technologien der nächsten Generation mehr denn je erforderlich sind, um die genetische Zusammensetzung eines Tumors aufzudecken. Und das ist noch nicht alles: Die Mutationssequenzen müssen identifiziert, segmentiert und im Hinblick auf das exprimierte Gen verarbeitet werden.
3. Sequenzierung von Genomen anderer Organismen
Das erste Genom, das sequenziert wurde, war das von Escherichia coliein einzelliger Organismus. Dann, Pflanzengenome wie Arabidopsis thaliana Mit jedem Grad an Komplexität, den diese Organismen aufwiesen, gewann die Genomsequenzierung an Bedeutung im Hinblick auf das Verständnis des Potenzials einer einzelnen Zelle, Krebszellen zu kontrollieren, zu sensibilisieren oder abzuwehren. Sie lieferte auch funktionierende Theorien über die Auslöser von Krebs. Jetzt analysieren die Forscher Echtzeitdaten von Zelllinien des Eierstockkrebses von Maus und Hühnerhamster, um die Methoden zur Krebserkennung zu erweitern oder zu verbessern und die Genauigkeit der derzeit verfügbaren Screening-Tests zu erhöhen.
4. Transkriptomanalyse für eine bessere Krebsüberwachung
Große Datenbanken mit Screening- und Versuchsdaten wurden erst in den letzten zehn Jahren im Rahmen von Krebsstudien erstellt. Dies hat einen entscheidenden Mehrwert für die Beibehaltung von Markergenen gebracht, die nun die ersten Werkzeuge für die Überwachung von Onkogenen, die Entdeckung von Medikamenten und Biokompatibilitätsstudien sind. Darüber hinaus extrapolieren einige Unternehmen Krebsgenomdaten zur Analyse von Transkriptomen und Proteinsynthese. Dies ist der Schlüssel zum Auffinden verlegter Genfragmente und ihrer Produkte und hilft somit bei der Verfolgung sowohl konservativer als auch nicht-konservativer Mutationen.
5. Einbindung von Algorithmen des maschinellen Lernens für die diagnostische Modellierung
In den Gesundheitssystemen werden enorme Datenmengen gespeichert, deren Nutzung durch moderne Technologien erleichtert wurde. Biotechnologische/interdisziplinäre Forscher führen umfangreiche Analysen dieser Datenbanken mit Hilfe von Hochgeschwindigkeits Algorithmen für maschinelles Lernen that can scan data, interact with data and ensure the highest accuracy in the integration of large databases. Maschinelles Lernen algorithms and high-tech data modelling systems are being employed to integrate cancer-related data from different sources in order to get a bigger picture of tumours. Genetic data visualization tools are making waves in cancer detection by enabling new methods to check cancer cell growth and death of healthy cells. This has been effectively put into use by incorporating the Genetic Modification and Clinical Research Information System, which are the most efficient open source research data management systems to visualize high throughput sequencing and screening data.
6. Größere Klarheit über die Krankheitsprognose
Einige Software-Tools zur Visualisierung von Gesundheitsdaten, wie z. B. die CancerLinQ have been developed, which enable physicians and interventionalists to get access to high-quality patient medical data. This is important because it helps understand previous cancer incidences, the progression of the disease and the previous treatment regimen. Doctors are referring to protected medical data of patients using screening tools and using it to recommend klinische Studien, suggest personalized treatment protocols and decide the scope of cancer management more effectively. Nowadays, hospitals that report high admission rates for cancer patients have also started using Tumor-ID-Karten die es ermöglichen, ihre Daten für die klinische Auswertung zentral zugänglich zu machen.
7. Klinische Daten bieten auch tragfähige Antworten für Krebsrückfälle
Immer mehr Leistungserbringer im Gesundheitswesen nutzen Datenanalysetools, um zu verstehen, warum bei einigen Patienten ein Tumorrezidiv auftritt und bei anderen nicht. Ärzte werten eine große Anzahl von Fallberichten aus, die helfen, die Gesundheitsrisiken von Patienten in einem viel größeren Rahmen als bisher zu bewerten. Medizinische Fallberichte werden zwar schon seit langem verwendet, aber erst jetzt werden sie immer zugänglicher und nützlicher. Das bedeutet, dass die Labordaten nicht den üblichen Identifizierungsverfahren unterworfen werden, sondern nach einem Vergleich mit anderen weltweit gemeldeten Fällen bewertet werden. Dies macht die Daten zur wichtigsten Voraussetzung für eine personalisierte Behandlung.
Krebs entwickelt sich schneller weiter als unsere Medikamente. Wenn man ihn besiegen, kontrollieren oder verhindern will, muss man seine Bemühungen daher unbedingt auf eine bessere Zielerkennung ausrichten. Big Data ist die entscheidende Technologie, die ein Krebsforscher einsetzen sollte, um die Qualität der Forschung zu verbessern und schneller die besten Ergebnisse zu erzielen.
_______________________________________
Konsultieren Sie einen Spezialist für Krebsforschungt oder freiberuflich Datenwissenschaftler auf Kolabtree.
Kolabtree helps businesses worldwide hire freelance scientists and industry experts on demand. Our freelancers have helped companies publish research papers, develop products, analyze data, and more. It only takes a minute to tell us what you need done and get quotes from experts for free.

Unlock Corporate Benefits
• Secure Payment Assistance
• Onboarding Support
• Dedicated Account Manager
Sign up with your professional email to avail special advances offered against purchase orders, seamless multi-channel payments, and extended support for agreements.


