



Dieser Beitrag erschien ursprünglich in meiner Kolumne auf der Website datengesteuerter Journalismus.
In meinem Im letzten Beitrag habe ich darüber gesprochen, wie Regression kann ein nützliches Instrument sein, um die verschiedenen Beziehungen zwischen Korrelationsvariablen herauszuarbeiten. Ich habe auch darüber gesprochen, dass Ausreißer problematisch sein können. Eine Möglichkeit, mit einem Ausreißer umzugehen, besteht darin, ihn einfach aus der Analyse zu streichen. Dadurch verringert sich die statistische Aussagekraft (die Wahrscheinlichkeit, einen signifikanten Prädiktor zu finden, wenn es ihn gibt) und es werden potenziell wertvolle Informationen aus dem Modell entfernt. Es könnte ein fruchtbareres Unterfangen sein, da wertvolle Informationen gewonnen werden können. Ich habe dies in meinem Beitrag darüber getan, wie sich Washington, DC von den anderen Staaten unterscheidet, und es hat mich auf eine Idee für eine weitere Kovariate gebracht, die zusätzlich zu den bereits berücksichtigten berücksichtigt werden sollte: Konzentration von Hassgruppen, % unversichert, % mit einem Bachelor-Abschluss oder höher und % in Armut.
In meinem Beitrag über die Merkmale von Washington, DC als Ausreißer Ich habe festgestellt, dass dieser Bezirk im Vergleich zu allen anderen Staaten am wenigsten weiß ist. Nur 40,2% der Distriktbevölkerung bezeichnen sich dort als weiß oder kaukasisch. Nur Hawaii hatte mit 25,4% einen geringeren Anteil an Weißen. Bei der Exit Poll für die Wahl im letzten Jahr stimmten 60% der weißen Frauen ohne Hochschulbildung für Trump, während es 71% der weißen Männer ohne Hochschulbildung taten. 74% der Nicht-Weißen stimmten für Clinton.
Durch die Aufnahme dieser Variablen in das Modell wurde die Genauigkeit des Modells mit DC deutlich verbessert, da 78,5% der Schwankungen bei Trumps Wahlbeteiligung berücksichtigt wurden. Die Variablen für Hassgruppen und % Armut waren nicht signifikant und wurden ausgeschlossen, da ihre Aufnahme in das Modell die statistische Aussagekraft verringert. Die Variablen % Bachelor, % Weiß und % Unversichert waren signifikant (d. h. der p-Wert ist kleiner als 0,05, was ich in einem späteren Beitrag erläutern werde), die anderen waren es nicht. Die Ausgabe der meisten Statistikpakete:
|
78,5% der Variabilität ausgemacht |
Koeffizienten |
Standardfehler |
t Status |
P-Wert |
Unter 95% |
Obere 95% |
|
Abfangen |
51.55 |
8.92 |
5.78 |
5.75E-07 |
33.61 |
69.48 |
|
%-Bachelor-Abschluss oder höher |
-1.11 |
0.15 |
-7.55 |
1.2E-09 |
-1.41 |
-0.82 |
|
% Weiß |
0.31 |
0.06 |
4.95 |
1.01E-05 |
0.18 |
0.43 |
|
% unversichert |
0.74 |
0.26 |
2.86 |
0.006319 |
0.22 |
1.26 |
Die Spalte "Koeffizienten" enthält die geschätzten Werte für die Regressionsgleichung, die ich in früheren Beiträgen dargelegt habe. Die aktuelle Gleichung lautet:
Trump % der Stimmen = 51,55 - 1,11*(% Bachelor) + 0,31*(% Weiß) + 0,74*(% Unversichert)
Das heißt, wenn alle Kovariaten gleich Null sind, wird für Trump ein Stimmenanteil von 51,55% vorhergesagt. Für jede Zunahme von 1% der % Junggesellen gibt es einen geschätzten Rückgang von Trumps Stimmen um 1,11%. Für jede 1% Zunahme der % weißen Bevölkerung im Staat gibt es eine geschätzte Zunahme von 0,31% und für jede 1% Zunahme der % Unversicherten im Staat.
Die Spalte mit der Bezeichnung "Standardfehler" ist eine Schätzung der Unsicherheit der Koeffizienten. Die Spalte "t stat" ist die Teststatistik zur Bestimmung, ob die Koeffizienten signifikant von Null verschieden sind. Der "p-Wert" ist die geschätzte Wahrscheinlichkeit, diesen geschätzten Koeffizienten zu beobachten, wenn der wahre Koeffizient Null ist. Wenn der p-Wert kleiner als 0,05 ist, wird davon ausgegangen, dass der wahre Koeffizient von Null verschieden ist. Die letzten beiden Spalten zeigen die oberen und unteren Grenzen für ein 95%-Konfidenzintervall für einen Koeffizienten. Das Konfidenzintervall besagt, dass der wahre Koeffizient in 95% der Fälle, in denen die Schätzungen vorgenommen werden, zwischen dem oberen und dem unteren Grenzwert liegt. Wenn in diesem Fall die obere und die untere Grenze die Zahl Null nicht überschreiten, bedeutet dies, dass der Koeffizient signifikant von Null verschieden ist.
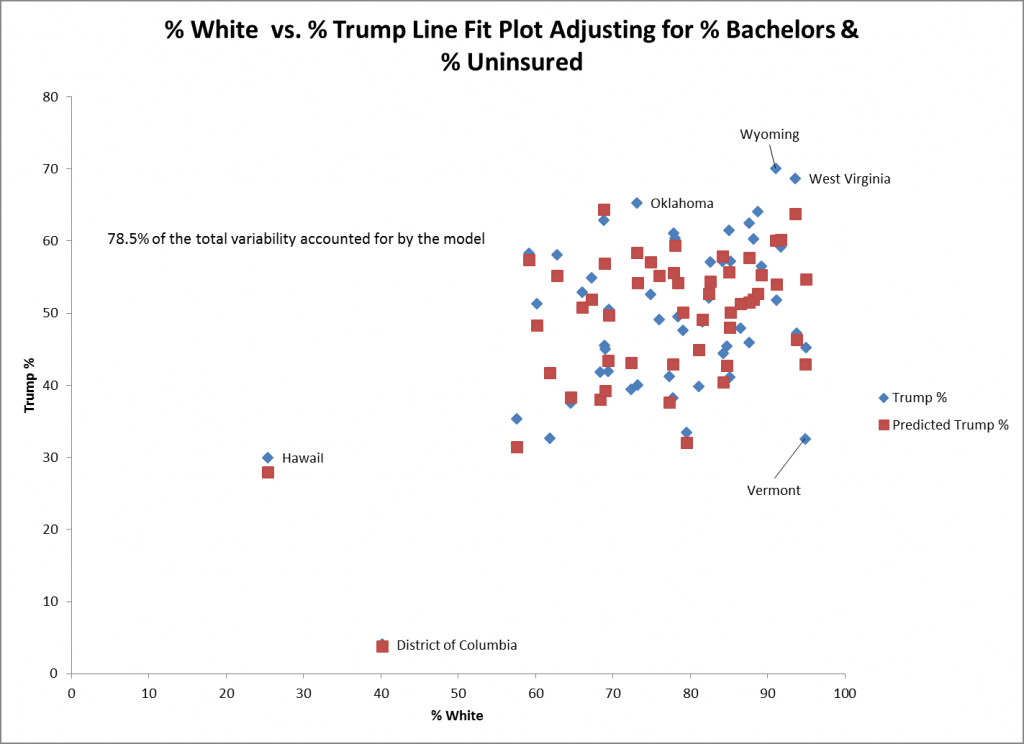
Das obige Streudiagramm zeigt die tatsächlichen (in der blauen Raute) und die vorhergesagten Werte (in den roten Quadraten) für % Weiß und % Trump für das Modell, das um % Junggesellen und % Unversicherte bereinigt ist. Die tatsächlichen und die vorhergesagten Werte für den District of Columbia (DC) und Hawaii liegen sehr nahe beieinander, was auf eine gute Anpassung schließen lässt. Ein Staat, der schlecht passt, ist Vermont, wo die tatsächliche Stimme für Trump 10% niedriger ist als die vorhergesagte Stimme, was direkt über der blauen Raute für Vermont zu sehen ist.
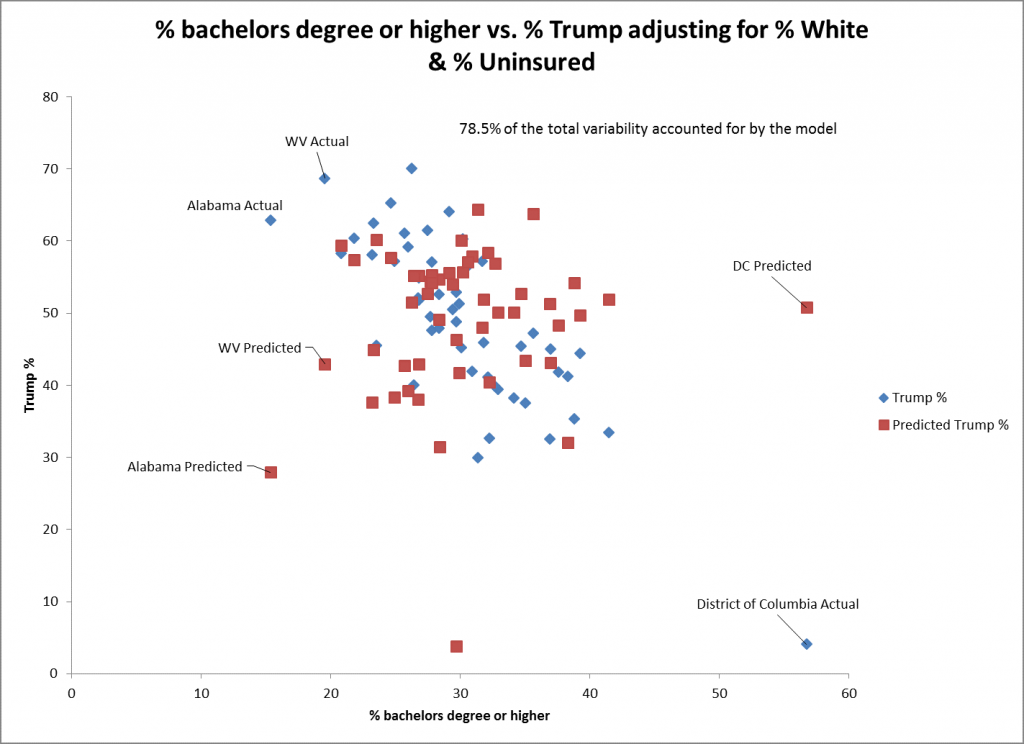
Das Streudiagramm für % bachelor's degree or higher deutet darauf hin, dass die Anpassung nicht so gut ist wie für % white als Prädiktor. Dies spiegelt sich in dem größeren Standardfehler für diesen Prädiktor (0,15) als für % weiß (0,06) wider. Die Vorhersage für DC ist für diesen Prädiktor nicht so gut, da er den höchsten Wert aufweist. Der Trend ist immer noch signifikant in die negative Richtung.
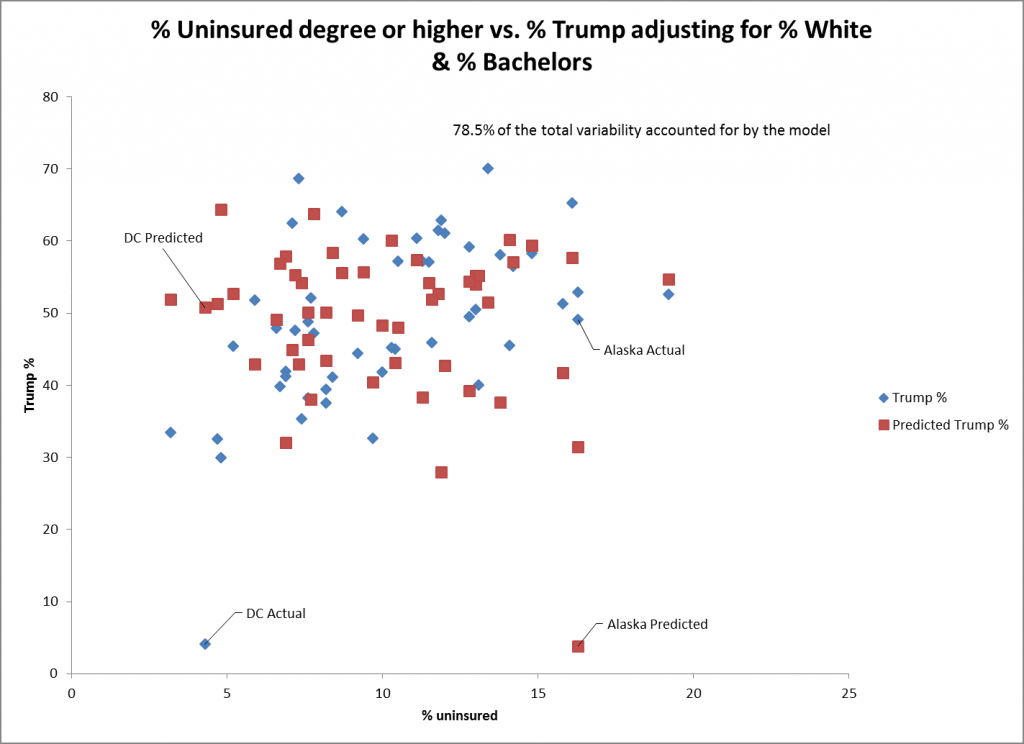
Das Streudiagramm für % Unversicherte als Prädiktor zeigt eine noch geringere Übereinstimmung mit Trumps % der Wählerstimmen. DC und Alaska sind unter vielen anderen Staaten schlecht geeignete Punkte für diesen Prädiktor. Der Standardfehler für diesen Prädiktor zeigt eine noch geringere Anpassung (0,26) für die anderen Prädiktoren, obwohl er immer noch statistisch signifikant ist.
Die multiple Regression ist ein potenziell leistungsfähiges Instrument, um die Beziehungen zwischen Vorhersagevariablen für ein bestimmtes Ergebnis herauszuarbeiten, wenn sie richtig durchgeführt wird. Die Hinzufügung der richtigen Kovariaten, wie z. B. der Rasse, kann dazu beitragen, die Auswirkungen eines Ausreißers wie Washington, DC, abzuschwächen. Es ist immer besser, alle Daten einzubeziehen, um ein möglichst vollständiges Bild der Situation zu erhalten.
Wir sehen nun, dass mit dem Anstieg des % der Bevölkerung eines Staates mit einem Bachelor-Abschluss oder höher das % der Stimmen für Trump sinkt. Gleichzeitig steigt das % der Stimmen für Trump, wenn der Anteil der Weißen und der Nichtversicherten in einem Staat steigt. Bei Vorhandensein dieser Variablen sind die Konzentration von Hassgruppen und der % des Staates in Armut keine signifikanten Prädiktoren mehr für die Wahl Trumps.
Während Trump und der von den Republikanern kontrollierte Kongress sich darauf vorbereiten, das Affordable Care Act (ACA oder wie die GOP sagt Obamacare) aufzuheben, schätzt das Congressional Budget Office, dass 23 Millionen Amerikaner in der Version des Repräsentantenhauses ihre Krankenversicherung verlieren werden und schätzungsweise 22 Millionen in der Version des Senats. In diesem Modell ist die Zahl der Nichtversicherten in jedem Bundesstaat positiv mit Trumps Stimmabgabe korreliert. Glaubt Trump, dass eine Erhöhung der Quote der Nichtversicherten seinen Stimmenanteil im Jahr 2020 erhöhen wird?
Armut wurde nicht mit der Wahl Trumps im Jahr 2016 in Verbindung gebracht. Der Rückgang der nicht versicherten Personen seit dem Inkrafttreten des ACA im Jahr 2014 ist hauptsächlich auf die Ausweitung von Medicaid für die ärmsten Personen und auf Subventionen zurückzuführen, die es Personen mit geringem Einkommen ermöglichen, eine Krankenversicherung abzuschließen. Eine Erhöhung der Zahl der Nichtversicherten könnte Trumps Wählerstimmen nicht verringern, aber es ist unwahrscheinlich, dass sie zunehmen.
Kolabtree helps businesses worldwide hire freelance scientists and industry experts on demand. Our freelancers have helped companies publish research papers, develop products, analyze data, and more. It only takes a minute to tell us what you need done and get quotes from experts for free.

Unlock Corporate Benefits
• Secure Payment Assistance
• Onboarding Support
• Dedicated Account Manager
Sign up with your professional email to avail special advances offered against purchase orders, seamless multi-channel payments, and extended support for agreements.


