



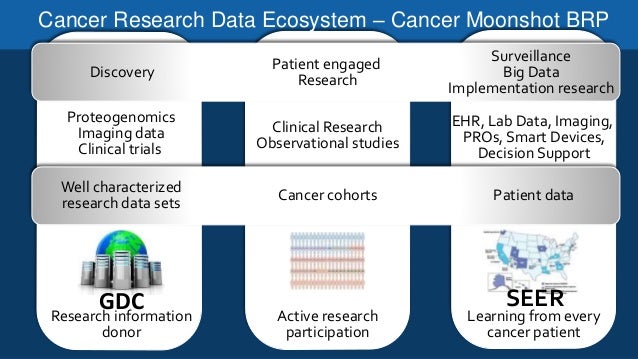
Data is ubiquitous in soins de santé—from hospitals, laboratories and recherche centres to surveillance systems, data makes up an indiscriminate part of healthcare systems. In fact, there is a myriad of types of data in biosciences research collected through clinical research or generated by genome sequencing or computational drug modelling. Recherche sur le cancer in particular benefits from the applications of big data and analytics. Cancer screening programs initiate rich repertoires of imaging and laboratory data, which require in-depth analysis and repeated testing in order for real value to be derived from it. Repeated testing and analyse des données enable clinical researchers to develop better drugs, understand their attributes in vivo et produire de nouveaux types de médicaments pour lutter contre le cancer.
Ce n'est pas un secret que données massives est considérée comme la méthode la plus sûre pour briser la complexité du cancer. La volonté d'établir de nouveaux mécanismes pour traiter le cancer a conduit les entreprises à étudier les outils de visualisation et d'analyse des données. La capture, la collecte, le stockage et l'analyse des données provenant des cellules cancéreuses est un tout nouveau jeu de balle dans lequel IA bienveillante, 10X Génomique, Médecine Insilico et NuMedii ont franchi leurs premiers jalons. In fact, 10X Genomics has gone the extra mile to provide whole genome sequencing, exome sequencing and single cell transcriptome analysis services that vividly indicate cancer-prone gene sequences in the DNA, mRNA and polypeptide chains, respectively. Few others are utilizing broader data frameworks, novel screening mechanisms and high definition data filtering algorithms to test cancer drugs on a wide range of cellular environments.
L'applicabilité du big data au diagnostic, à l'expérimentation et à la gestion du cancer est saluée comme l'étape essentielle vers une recherche sur le cancer de niveau supérieur. Voici sept façons dont le big data influence la recherche sur le cancer.
1. Séquençage des génomes du cancer chez l'homme

Chaque cellule de notre corps possède le même nombre de chromosomes et à peu près le même volume d'ADN. Mais les cellules cancéreuses présentent des aberrations distinctes au niveau du contenu chromosomique et de la croissance, qui, si elles sont soumises à une visualisation in silico, peuvent être utilisées pour exploiter les informations jusqu'au niveau de l'ADN. Ces études de séquençage peuvent aider les biologistes cellulaires, les bioinformaticiens, les biologistes moléculaires et les nanobiotechnologues à mettre au point de meilleures méthodes pour éliminer les anomalies chromosomiques, ce qui peut déboucher sur d'éventuelles voies thérapeutiques.
2. Séquençage à haut débit d'échantillons de patients
Nous sommes à l'ère où la médecine personnalisée devient monnaie courante dans le domaine des soins de santé et le cancer est le principal champ d'application de ce progrès. Ce mouvement vers la médecine personnalisée a mis l'accent sur la biologie computationnelle, la branche de la biologie qui rend les soins de santé aussi sophistiqués qu'ils sont perçus aujourd'hui. Professeur Olivier ElementoL'équipe de l'Université de Cornell, experte en médecine informatique, souligne que les cellules cancéreuses sont toujours en train de changer, d'évoluer et de s'adapter à l'environnement humain, et que des technologies de nouvelle génération plus rapides sont plus que jamais nécessaires pour découvrir la composition génétique d'une tumeur. Et l'effort ne s'arrête pas là, les séquences de mutation doivent être identifiées, segmentées et traitées en fonction du gène exprimé.
3. Séquençage des génomes d'autres organismes
Le premier génome à avoir été séquencé est celui du Escherichia coliun organisme unicellulaire. Ensuite, les génomes des plantes comme Arabidopsis thaliana et des vers non vertébrés, des reptiles et des rongeurs ont été séquencés. Avec chaque degré de complexité que présentaient ces organismes, le séquençage du génome a gagné en importance en termes de compréhension du potentiel d'une seule cellule à contrôler, sensibiliser ou éloigner les cellules cancéreuses. Il a également permis de présenter des théories de travail sur les déclencheurs du cancer. Aujourd'hui, les chercheurs analysent des données en temps réel provenant de lignées de cellules cancéreuses de l'ovaire de hamster de souris ou de poulet afin d'augmenter ou d'améliorer les méthodes de détection du cancer, tout en augmentant la précision des tests de dépistage actuellement disponibles.
4. Analyse du transcriptome pour un meilleur suivi du cancer
Au cours de la dernière décennie, de grandes bases de données de dépistage et de données expérimentales ont été générées uniquement lors d'études liées au cancer. Cela a ajouté une valeur cruciale au maintien des gènes marqueurs qui sont maintenant les outils de première main pour la surveillance des oncogènes, la découverte de médicaments et les études de biocompatibilité. En outre, certaines entreprises extrapolent les données du génome du cancer pour analyser les transcriptomes et la synthèse des protéines. C'est la clé pour trouver des fragments de gènes mal placés et leurs produits, ce qui permet de suivre les mutations, qu'elles soient conservatrices ou non.
5. Incorporation d'algorithmes d'apprentissage automatique pour la modélisation du diagnostic
Les systèmes de soins de santé stockent d'énormes quantités de données, que les technologies modernes permettent d'exploiter plus facilement. Les chercheurs en biotechnologie et les chercheurs interdisciplinaires effectuent de vastes analyses de ces bases de données à l'aide de technologies à haut débit. algorithmes d'apprentissage automatique that can scan data, interact with data and ensure the highest accuracy in the integration of large databases. Apprentissage automatique algorithms and high-tech data modelling systems are being employed to integrate cancer-related data from different sources in order to get a bigger picture of tumours. Genetic data visualization tools are making waves in cancer detection by enabling new methods to check cancer cell growth and death of healthy cells. This has been effectively put into use by incorporating the Genetic Modification and Clinical Research Information System, which are the most efficient open source research data management systems to visualize high throughput sequencing and screening data.
6. Présenter une plus grande clarté sur le pronostic de la maladie
Certains outils logiciels de visualisation des données sur les soins de santé, tels que l'application CancerLinQ have been developed, which enable physicians and interventionalists to get access to high-quality patient medical data. This is important because it helps understand previous cancer incidences, the progression of the disease and the previous treatment regimen. Doctors are referring to protected medical data of patients using screening tools and using it to recommend les essais cliniques, suggest personalized treatment protocols and decide the scope of cancer management more effectively. Nowadays, hospitals that report high admission rates for cancer patients have also started using Cartes d'identification des tumeurs qui permettent à leurs données d'être accessibles de manière centralisée pour une évaluation clinique.
7. Les données cliniques apportent également des réponses viables aux rechutes du cancer
De plus en plus de prestataires de soins de santé se tournent vers les outils d'analyse de données pour comprendre les raisons pour lesquelles certains patients présentent des tumeurs récurrentes alors que d'autres non. Les médecins évaluent un grand nombre de rapports de cas qui permettent d'évaluer les risques pour la santé des patients dans une perspective beaucoup plus large qu'auparavant. Si les rapports de cas médicaux sont utilisés depuis longtemps, ce n'est que maintenant que leur accessibilité et leur utilité augmentent. Les données de laboratoire ne sont donc pas soumises à des processus d'identification standard, mais évaluées après comparaison avec d'autres cas signalés dans le monde. Les données deviennent ainsi la condition essentielle d'un traitement personnalisé.
Le cancer évolue à une vitesse supérieure à celle de nos médicaments. Par conséquent, si vous cherchez à le vaincre, à le contrôler ou à le prévenir, il est impératif de canaliser les efforts grâce à une meilleure reconnaissance des cibles. Le big data est cette technologie essentielle qu'un cancérologue devrait appliquer pour améliorer la qualité de la recherche et obtenir plus rapidement les meilleurs résultats.
_______________________________________
Consultez un Spécialiste de la recherche sur le cancert ou freelance spécialiste des données sur Kolabtree.
Kolabtree helps businesses worldwide hire freelance scientists and industry experts on demand. Our freelancers have helped companies publish research papers, develop products, analyze data, and more. It only takes a minute to tell us what you need done and get quotes from experts for free.

Unlock Corporate Benefits
• Secure Payment Assistance
• Onboarding Support
• Dedicated Account Manager
Sign up with your professional email to avail special advances offered against purchase orders, seamless multi-channel payments, and extended support for agreements.


