



この記事は、サイト内の私のコラムに掲載されたものです。 データ駆動型ジャーナリズム.
私の中で 前回の記事で、回帰の方法についてお話しました。 は、相関変数間のさまざまな関係を切り分けるのに有効なツールです。また、外れ値が問題になることもあることをお話しました。外れ値に対処する方法の1つは、単純に分析対象から外すことです。そうすると、統計的検出力(有意な予測変数が存在するときに、それが見つかる確率)が低下し、モデルから潜在的に価値のある情報が削除されます。貴重な情報を得ることができるため、より実りある努力になるかもしれません。私は、ワシントンDCと他の州との違いについての投稿でこれを行い、すでに考慮されているものに加えて考慮すべき別の共変量についてのアイデアを得ました:憎悪集団の集中、%無保険、学士号以上を持つ%、貧困層%。
私の中で 異常値としてのワシントンDCの特徴に関する投稿 検討したどの州と比べても、最も白人の少ない州であることがわかりました。地区人口のうち、白人またはコーカソイドとして認識されているのは、わずか40.2%です。ハワイ州だけが25.4%で、より少ない%の白人であった。昨年の選挙の出口調査では、大学教育を受けていない白人女性の60%がトランプに投票したのに対し、大学教育を受けていない白人男性の71%はトランプに投票した。非白人の74%はクリントンに投票した。
それをモデルに加えることで、DCを含めたモデルの精度が大幅に向上し、トランプ票の変動の78.5%が説明された。ヘイトグループと%貧困の変数は有意ではなく、モデルに入れると統計的検出力が低下するため除外した。%学士、%白人、%無保険の変数は有意(p値が0.05未満であることを意味する...今後の記事で説明する)で、その他は有意でなかった。ほとんどの統計パッケージの出力です。
|
78.5%の変動幅 りょうしょうずみ |
係数 |
標準誤差 |
Tスタット |
P値 |
下 95% |
アッパー 95% |
|
インターセプト |
51.55 |
8.92 |
5.78 |
5.75E-07 |
33.61 |
69.48 |
|
%学士号 以上 |
-1.11 |
0.15 |
-7.55 |
1.2E-09 |
-1.41 |
-0.82 |
|
% ホワイト |
0.31 |
0.06 |
4.95 |
1.01E-05 |
0.18 |
0.43 |
|
% 保険未加入 |
0.74 |
0.26 |
2.86 |
0.006319 |
0.22 |
1.26 |
係数」と書かれた欄には、以前の記事で綴った回帰式の推定値が記載されています。現在の式はこうなっています。
トランプ %の得票=51.55-1.11*(%学士)+0.31*(%白人)+0.74*(%無保険者)
これは、すべての共変量がゼロに等しいとき、トランプは51.55%の票を獲得すると予測されることを示している。%の学士が1%増えるごとに、トランプの得票が1.11%減少すると推定される。州内の白人人口が%増加するごとに0.31%、州内の無保険者が%増加するごとに0.31%増加すると予測される。
標準誤差と書かれた列は、係数の不確かさの推定値である。t stat "とラベル付けされた列は、係数がゼロから有意に異なるかどうかを決定するための検定統計量である。p値」は、真の係数がゼロであるときに、この推定係数を観測する推定確率である。慣習的に、p値が0.05より小さいとき、我々は真の係数がゼロと異なると結論づける。最後の2列は、係数の95%信頼区間の上界と下界を示す。信頼区間は、推定がなされた時間のうち95%は、真の係数が上限と下限の間にあることを意味します。この場合、もし上下限がゼロをまたがなければ、それは係数がゼロから有意に異なることと等しい。
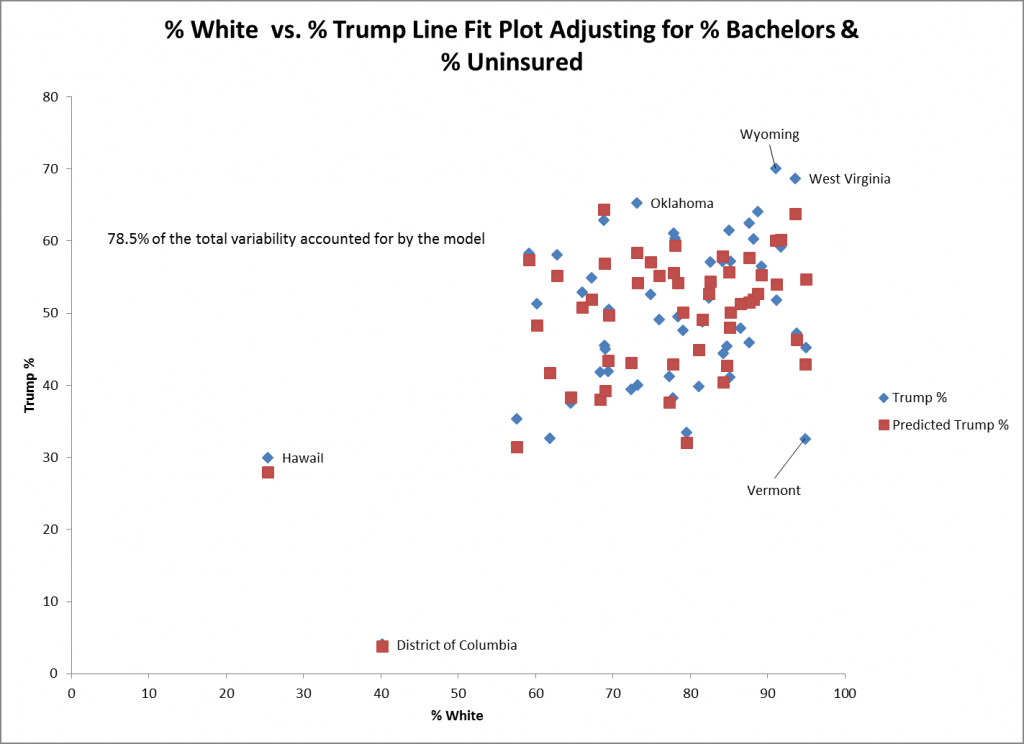
上の散布図は、%独身者と%無保険者を調整したモデルについて、%白人と%トランプの実績値(青菱)と予測値(赤四角)を示したものである。コロンビア特別区(DC)とハワイ州の実績値と予測値は非常に近く、適合度が高いことがうかがえる。バーモント州の青い菱形の真上にあるように、トランプ氏の実際の投票が予測値より10%低いのである。
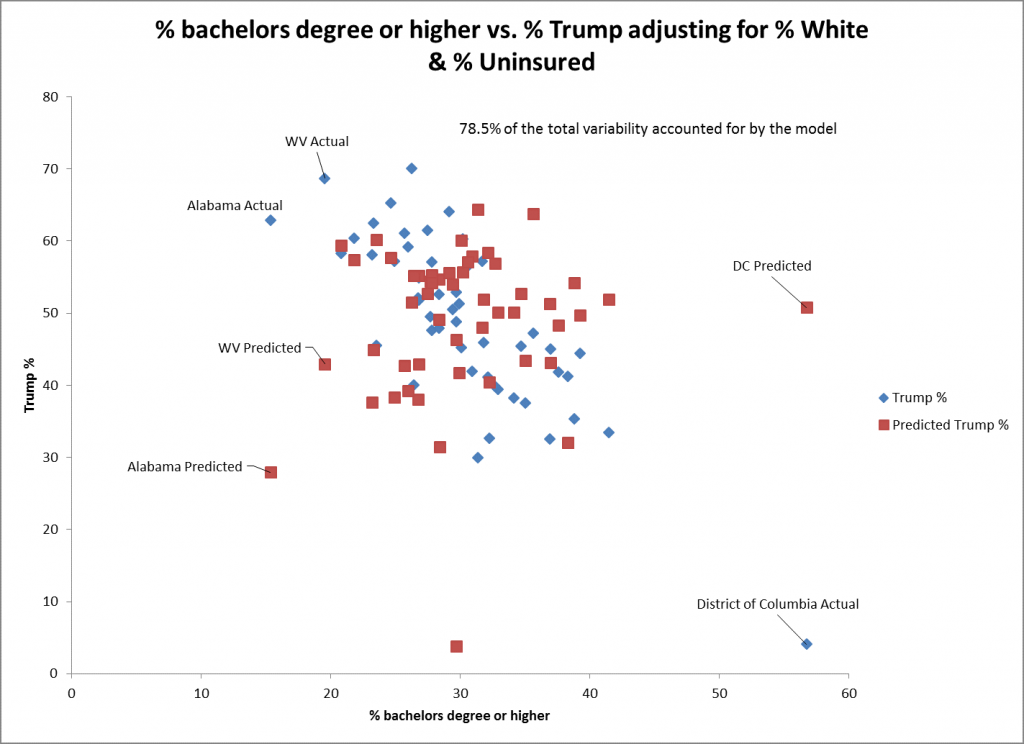
%学士以上」の散布図を見ると、「%白人」を予測変数とした場合ほど適合度が高くないことがわかる。これは、この予測変数の標準誤差(0.15)が%白人のもの(0.06)より大きいことに反映されている。DCの予測は、この予測変数が最も高いので、それほど良いとは言えない。この傾向は、依然として負の方向で有意である。
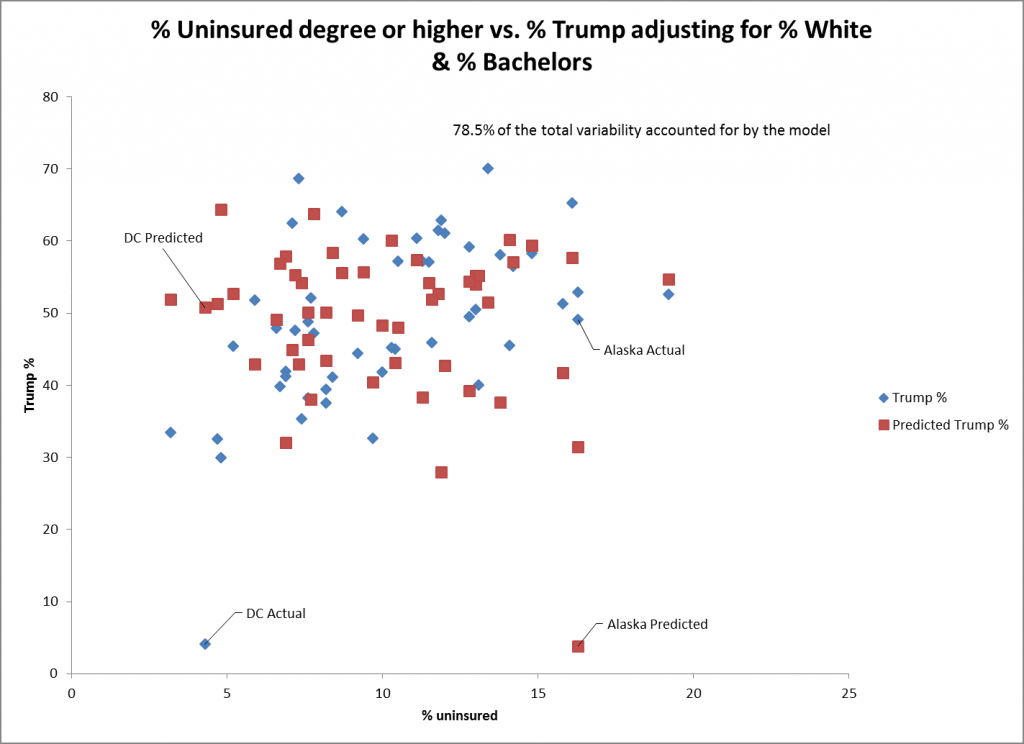
%の無保険者を予測因子とした散布図では、トランプの%の得票に対してさらに適合度が低いことがわかる。他の多くの州の中でもDCとアラスカはこの予測変数の適合性が低い点である。この予測変数の標準誤差は,まだ統計的に有意であるにもかかわらず,他の予測変数の適合度(0.26)をさらに低く示している.
重回帰は、正しく実施されれば、特定の結果に対する予測変数間の関係を明らかにするための強力なツールとなる可能性があります。人種などの適切な共変数を加えることで、ワシントンDCのような異常値の影響を緩和することができる。可能な限り完全なイメージを与えるために、すべてのデータを含めることは常に良いことです。
学士号以上の人口が増えるほど、トランプ氏への投票率は下がることがわかります。同時に、ある州の白人と無保険者の割合が増えると、トランプの得票の%は増加する。これらの変数がある場合、ヘイトグループの集中度や貧困状態の州の%は、もはやトランプの票の有意な予測因子ではない。
トランプと共和党が支配する議会がAffordable Care Act(ACA、またはGOPが言うところのObamacare)の廃止を準備している中、議会予算局は下院版で2300万人、上院版で2200万人のアメリカ人が健康保険を失うと推定しています。このモデルでは、各州の無保険率はトランプ氏の投票と正の相関がある。トランプは、無保険率を上げることで2020年の投票率が上がると考えているのだろうか。
2016年のトランプ氏の投票に貧困は関連していない。2014年にACAが施行されて以来、保険未加入者の推計値が減少したのは、貧困層に対するメディケイドの拡大や低所得者が医療保険に加入できるようにする補助金によるものがほとんどである。無保険者を増やしても、トランプ氏の票は減らないかもしれないが、増えることはまずない。
Kolabtree helps businesses worldwide hire freelance scientists and industry experts on demand. Our freelancers have helped companies publish research papers, develop products, analyze data, and more. It only takes a minute to tell us what you need done and get quotes from experts for free.

Unlock Corporate Benefits
• Secure Payment Assistance
• Onboarding Support
• Dedicated Account Manager
Sign up with your professional email to avail special advances offered against purchase orders, seamless multi-channel payments, and extended support for agreements.


