



Questo post è apparso originariamente nella mia rubrica sul sito giornalismo guidato dai dati.
Nel mio ultimo post ho parlato di come la regressione può essere uno strumento utile per distinguere le diverse relazioni tra le variabili correlazionali. Ho anche parlato di come i valori anomali possono essere problematici. Un modo di trattare un outlier è semplicemente quello di eliminarlo dall'analisi. Così facendo si riduce la potenza statistica (la probabilità di trovare un predittore significativo quando esiste) e si rimuovono informazioni potenzialmente preziose dal modello. Potrebbe essere un'impresa più fruttuosa in quanto si possono ottenere informazioni preziose. Ho fatto questo nel mio post su come Washington, DC differisce dagli altri stati e mi ha dato un'idea per un'altra covariata che dovrebbe essere considerata in aggiunta a quelle già considerate: concentrazione di gruppi di odio, % non assicurati, % con un diploma di laurea o superiore, e % in povertà.
Nel mio post sulle caratteristiche di Washington, DC come un outlier Ho scoperto che è il meno bianco di tutti gli stati considerati. Solo il 40,2% della popolazione dei distretti si identifica come bianca o caucasica. Solo le Hawaii hanno un % bianco più piccolo, al 25,4%. Nell'exit poll per le elezioni dell'anno scorso, 60% delle donne bianche senza istruzione universitaria hanno votato per Trump, mentre 71% dei maschi bianchi senza istruzione universitaria. Il 74% dei non bianchi ha votato per la Clinton.
Aggiungere questo al modello ha migliorato significativamente la precisione del modello con DC incluso con il 78,5% della variabilità del voto di Trump rappresentato. Le variabili per i gruppi d'odio e la povertà % non erano significative e sono state escluse perché averle nel modello diminuisce la potenza statistica. Le variabili % scapolo, % bianco, e % non assicurato erano significative (il che significa che il p-value è inferiore a 0,05 che spiegherò in un futuro post), le altre no. L'output della maggior parte dei pacchetti statistici:
|
78.5% della variabilità tenuto conto di |
Coefficienti |
Errore standard |
t Stato |
P-value |
Inferiore 95% |
Superiore 95% |
|
Intercettare |
51.55 |
8.92 |
5.78 |
5.75E-07 |
33.61 |
69.48 |
|
% laurea di primo livello o superiore |
-1.11 |
0.15 |
-7.55 |
1.2E-09 |
-1.41 |
-0.82 |
|
% Bianco |
0.31 |
0.06 |
4.95 |
1.01E-05 |
0.18 |
0.43 |
|
% non assicurato |
0.74 |
0.26 |
2.86 |
0.006319 |
0.22 |
1.26 |
La colonna etichettata "coefficienti" dà i valori stimati per l'equazione di regressione che ho spiegato nei post precedenti. L'equazione attuale recita
Trump % del voto = 51,55 - 1,11*(% celibe) + 0,31*(% bianco) + 0,74*(% non assicurato)
Questo dice che quando tutte le covariate sono uguali a zero, si prevede che Trump abbia il 51,55% dei voti. Per ogni aumento di 1% degli scapoli % c'è una diminuzione stimata di 1,11% nel voto di Trump. Per ogni aumento di 1% nella popolazione bianca % nello stato c'è un aumento stimato di 0,31% e per ogni aumento di 1% nel % dei non assicurati nello stato.
La colonna etichettata "errore standard" è una stima dell'incertezza nei coefficienti. La colonna etichettata "t stat" è la statistica del test per determinare se i coefficienti sono significativamente diversi da zero. Il "p-value" è la probabilità stimata di osservare questo coefficiente stimato quando il coefficiente vero è zero. Per convenzione, quando il p-value è inferiore a 0,05 si conclude che il vero coefficiente è diverso da zero. Le ultime due colonne mostrano i limiti superiore e inferiore di un intervallo di confidenza 95% per un coefficiente. L'intervallo di confidenza dice che il 95% delle volte che le stime sono fatte, il vero coefficiente sarà tra i limiti superiore e inferiore. In questo caso, se i limiti superiore e inferiore non sono a cavallo del numero zero, ciò equivale al fatto che il coefficiente è significativamente diverso da zero.
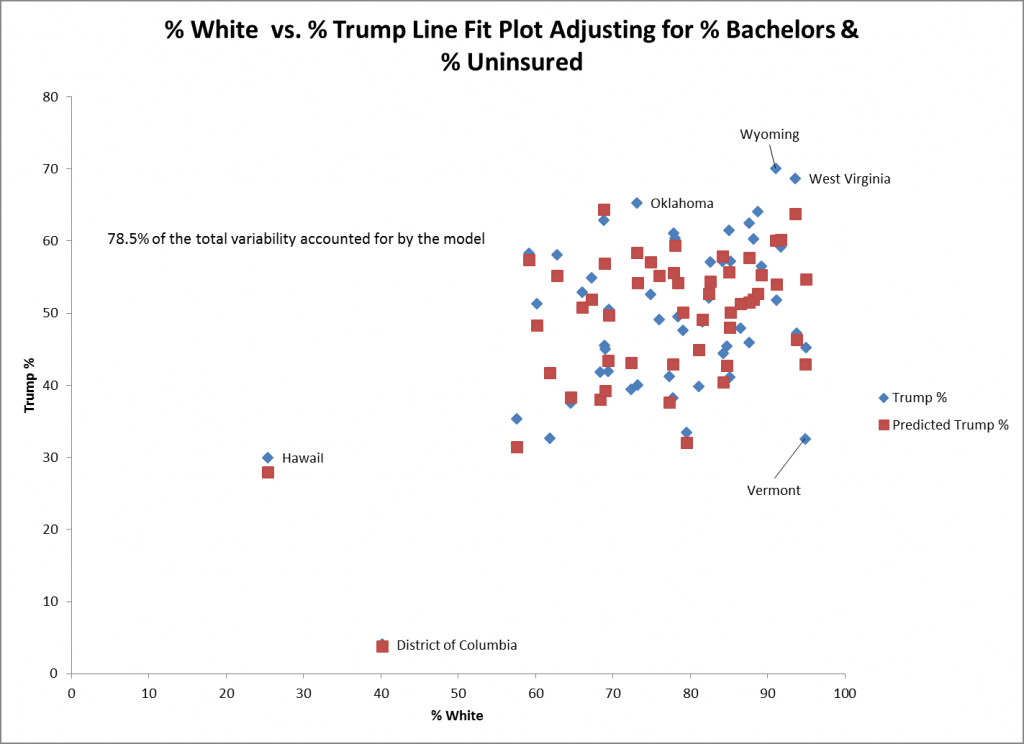
Il grafico a dispersione sopra mostra i valori effettivi (nel diamante blu) e previsti (nei quadrati rossi) per % bianco e % Trump per il modello che aggiusta per % celibi e % non assicurati. I valori reali e previsti per il Distretto di Columbia (DC) e le Hawaii sono molto vicini l'uno all'altro, il che suggerisce un buon adattamento. Uno stato che si adatta male è il Vermont dove il voto effettivo per Trump è 10% più basso del voto previsto che può essere visto direttamente sopra il diamante blu per il Vermont.
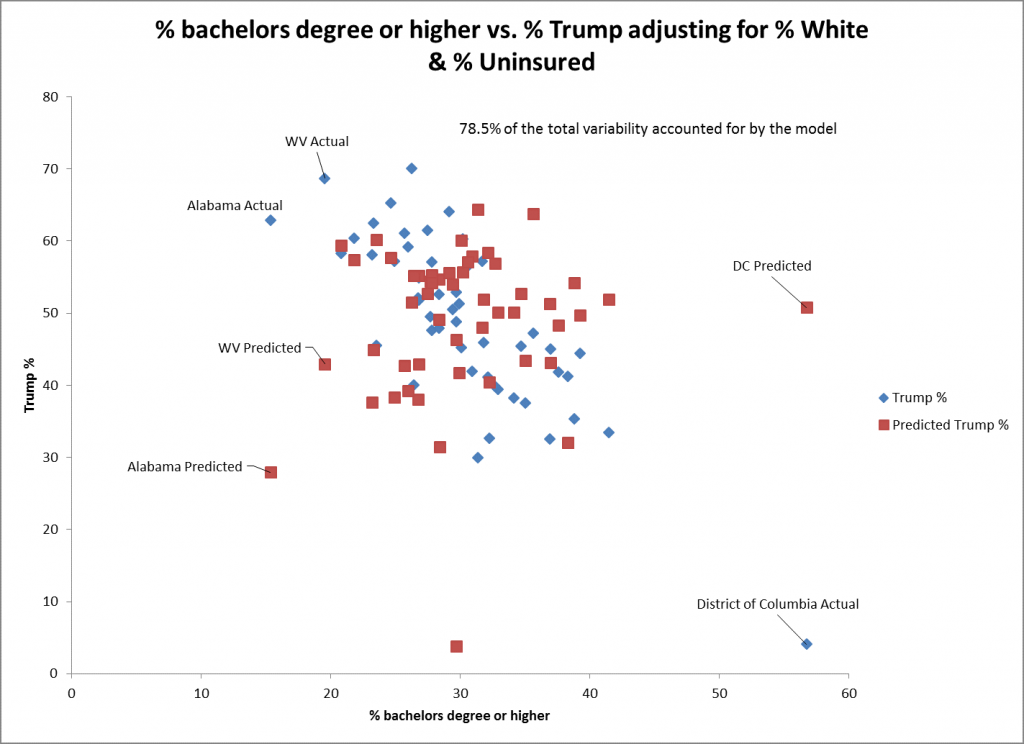
Il grafico di dispersione per % laurea o superiore suggerisce che l'adattamento non è così buono come quello per % bianco come predittore. Questo si riflette nell'errore standard maggiore per questo predittore (0,15) che per l'% bianco (0,06). La predizione per DC non è altrettanto buona per questo predittore che ha il più alto. La tendenza è ancora significativa nella direzione negativa.
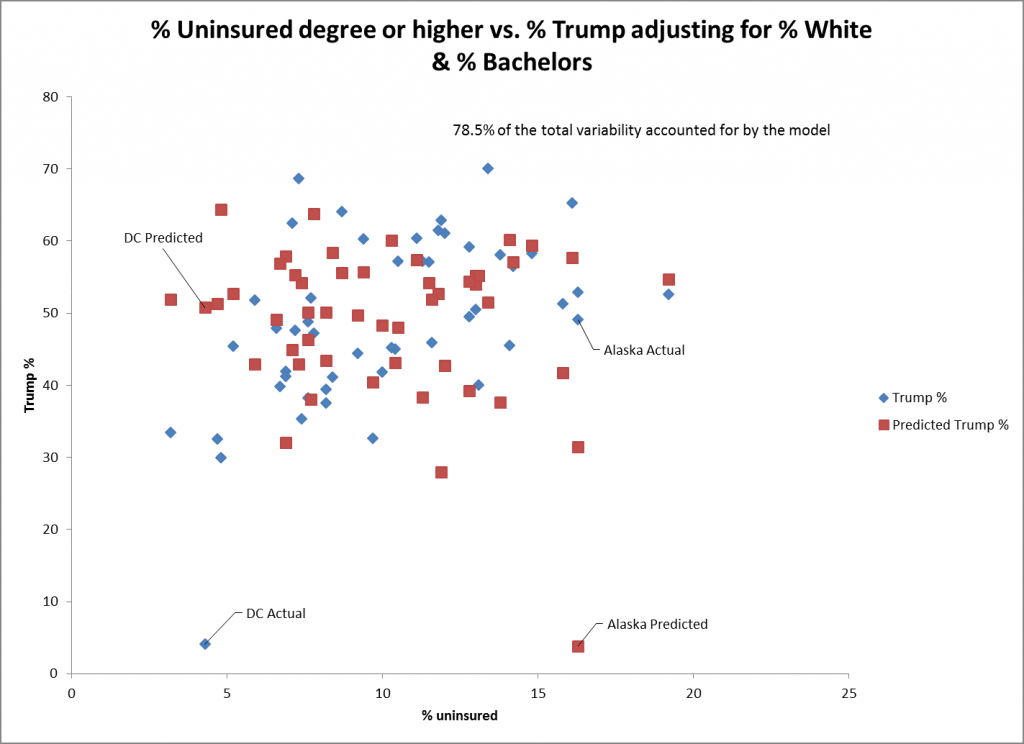
Lo scatterplot per il % non assicurato come predittore mostra ancora meno fit per il % del voto di Trump. DC e Alaska sono punti poco adatti per questo predittore tra molti altri stati. L'errore standard per questo predittore mostra un adattamento ancora minore (0,26) per gli altri predittori, sebbene sia ancora statisticamente significativo.
La regressione multipla è uno strumento potenzialmente potente per distinguere le relazioni tra le variabili predittive di un risultato specifico, se condotta correttamente. Aggiungere le giuste covariate come la razza può aiutare ad alleviare gli effetti di un outlier come Washington, DC. È sempre meglio includere tutti i dati per dare un quadro il più completo possibile.
Ora vediamo che come il % della popolazione di uno stato con un diploma di laurea o superiore aumenta il % del voto per Trump diminuisce. Allo stesso tempo, come aumentano le percentuali dei bianchi e dei non assicurati in uno stato, aumenta la % del voto di Trump. In presenza di queste variabili la concentrazione di gruppi di odio e l'% dello stato in povertà non sono più predittori significativi del voto di Trump.
Mentre Trump e il congresso controllato dai repubblicani si preparano ad abrogare l'Affordable Care Act (ACA o come dice il GOP Obamacare), il Congressional Budget Office stima che 23 milioni di americani perderanno la loro assicurazione sanitaria nella versione della Camera della legge e si stima che 22 milioni la perderanno nella versione del Senato. In questo modello il tasso di non assicurati in ogni stato è positivamente correlato al voto di Trump. Trump crede che aumentare il tasso di non assicurati aumenterà la sua quota di voti nel 2020?
La povertà non è stata associata al voto di Trump nel 2016. La diminuzione delle stime dei non assicurati da quando l'ACA è entrata in vigore nel 2014 è dovuta principalmente all'espansione di Medicaid per gli individui più poveri e ai sussidi che permettono agli individui a più basso reddito di acquistare un'assicurazione sanitaria. L'aumento del numero di non assicurati potrebbe non diminuire il voto di Trump, ma è improbabile che lo aumenti.
Kolabtree helps businesses worldwide hire freelance scientists and industry experts on demand. Our freelancers have helped companies publish research papers, develop products, analyze data, and more. It only takes a minute to tell us what you need done and get quotes from experts for free.

Unlock Corporate Benefits
• Secure Payment Assistance
• Onboarding Support
• Dedicated Account Manager
Sign up with your professional email to avail special advances offered against purchase orders, seamless multi-channel payments, and extended support for agreements.


