



Questo post è stato scritto da Paolo Ricci, un esperto di Kolabtree. È apparso originariamente nella sua rubrica su Giornalismo guidato dai dati.
Questo articolo descrive come il test esatto di Fisher può essere usato per le tabelle di contingenza di piccoli campioni. Un problema comune in analisi dei dati è come determinare se c'è una relazione statistica tra due variabili categoriche come il genere, la razza o la quota di voto per due candidati in un'elezione. Il modo più semplice per visualizzare la relazione è quello di rappresentare i conteggi per ogni combinazione di due variabili in una tabella di contingenza con le righe che rappresentano i livelli di una variabile e le colonne che rappresentano i livelli dell'altra variabile. Il test statistico più comunemente usato per un'associazione tra le variabili di riga e di colonna è il chi-quadro (χ2) test. L'esempio nella tabella seguente è dato per illustrare il test.
| Vincitore democratico (% della colonna) | Totale | ||
| Vittoria di Clinton | Vittoria di Sanders | ||
| Trump 1° | 25 (86%) | 12 (55%) | 37 |
| Trump 2° | 3 (11%) | 8 (36%) | 11 |
| Trump 3° | 1 (3%) | 2 (9%) | 3 |
| Totale | 29 (100%) | 22 (100%) | 51 |
Le colonne della tabella qui sopra mostrano gli stati primari vinti da Hillary Clinton e da Bernie Sanders sul lato democratico e Donald Trump piazzato negli stessi stati primari sul lato repubblicano. Il numero totale di stati nella tabella è 51 perché è incluso il Distretto di Columbia. Le percentuali della colonna mostrano che Trump ha vinto 86% degli stati primari vinti dalla Clinton mentre ha vinto 55% degli stati vinti da Sanders.
Il test chi-quadro si basa sul calcolo dei valori attesi per ogni cella della tabella. Per esempio, il valore atteso (il valore per la cella che ci si aspetterebbe di vedere se non ci fosse alcuna relazione tra le variabili) per la cella per gli stati in cui Trump è arrivato terzo nella parte repubblicana e per gli stati in cui Bernie Sanders ha vinto nella parte democratica sarebbe calcolato moltiplicando il totale della riga per gli stati in cui Trump è arrivato terzo (3) per il totale della colonna per gli stati in cui Sanders ha vinto (22). Questo prodotto viene poi diviso per il numero totale di osservazioni (51). La formula per il valore atteso è data da:
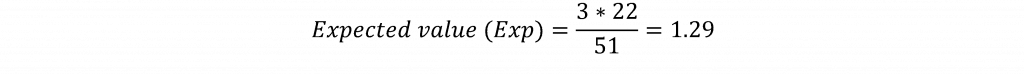
Ciò significa che per questa cella ci si aspetterebbe un valore di 1,29 se gli stati primari in cui Trump è arrivato terzo e Sanders ha vinto fossero completamente indipendenti l'uno dall'altro. Il valore osservato per questa cella è 2, suggerendo un conteggio più alto per questa cella di quanto ci si aspetterebbe. I valori attesi verrebbero calcolati per ogni cella della tabella e la differenza tra i valori osservati e quelli attesi per ogni cella viene calcolata, squadrata, divisa per il valore atteso e sommata tra le celle della tabella secondo la formula:
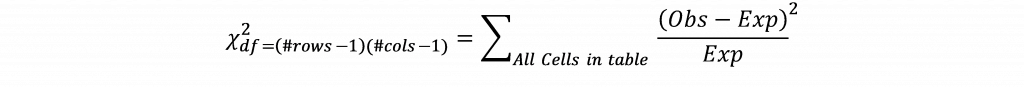
Se il valore del chi-quadro supera il valore critico del chi-quadro per un dato grado di libertà (trovato moltiplicando il numero di righe meno uno e il numero di colonne meno uno) e il valore p, si conclude che c'è un'associazione tra le variabili.
C'è un problema con il test del chi-quadro. È un'approssimazione della distribuzione dei conteggi nelle tabelle di contingenza. Se più di 20% delle celle della tabella hanno un valore atteso inferiore a cinque, l'approssimazione del chi-quadrato non funziona per testare l'ipotesi di un'associazione tra la variabile di riga e la variabile di colonna (come nel caso della tabella sottostante). Entrambe le variabili nella tabella sono categoriche. I principali pacchetti statistici avvisano l'utente se questa assunzione viene violata. La violazione dell'ipotesi fa sì che il valore p osservato non sia corretto e può portare a conclusioni errate sulla presenza o l'assenza di un'associazione. Esiste un'alternativa esatta al test chi-quadrato chiamata test esatto di Fisher.
Il test esatto di Fisher si basa sulla distribuzione di probabilità ipergeometrica.
![]()
Qui il Ri! sono i fattoriali dei totali di riga (5!=5*4*3*2*1), Ci! sono i fattoriali dei totali delle singole colonne, N! è il fattoriale del totale della tabella e l'aijsono i fattoriali per i valori delle singole celle. Il Πij è il coefficiente prodotto dei valori delle singole celle. Una formula di questo tipo è ancora più impegnativa dal punto di vista computazionale rispetto al test del chi-quadro, soprattutto per tabelle con molte righe e colonne. Per questo motivo il test chi-quadro era favorito in passato, perché richiedeva troppa memoria per essere eseguito dai computer. Oggi il test esatto di Fisher è meno problematico per i computer ed è facile da eseguire nei principali pacchetti statistici (R, SAS, SPSS), STATA, ecc.).
I comandi per condurre il test esatto di Fisher e il test chi-quadrato in R (un programma gratuito) possono essere visti qui sotto per la tabella in cima all'articolo con l'output corrispondente (giallo per il test esatto di Fisher, verde per il test chi-quadrato).
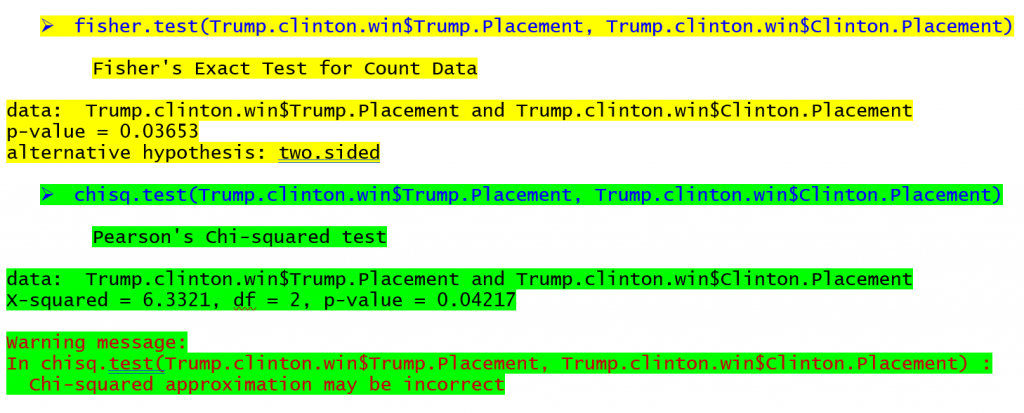
L'output del test esatto di Fisher mostra che c'è una probabilità di 0,03653 di osservare queste frequenze nella tabella quando non c'è associazione tra le righe e le colonne. L'output del test chi-quadro mostra una probabilità di 0,04217 per una relazione nella stessa tabella. Se usassimo il valore di .05 p come criterio di significatività, troveremmo una relazione per entrambi i test in questo caso, anche se i valori di p differiscono. Gli stati che Hillary Clinton ha vinto nella stagione delle primarie hanno avuto più probabilità di essere vinti da Donald Trump, mentre gli stati in cui Bernie Sanders ha vinto hanno avuto più probabilità di far finire Trump 2e o 3rd In tabelle con dimensioni del campione ancora più piccole, la differenza tra i p-valori può essere ancora maggiore e portare a conclusioni radicalmente diverse.
Come avvertimento, il valore p non dovrebbe essere usato come indicatore della forza dell'associazione tra variabili categoriche. O il test è significativo o no. Il valore p è sensibile alla dimensione del campione. Spesso l'odds ratio è usato per stimare la dimensione dell'effetto, ma R lo calcola solo nella funzione fisher.test per tabelle con 2 colonne e 2 righe.
Il test esatto di Fisher fornisce un criterio per decidere se le differenze nelle percentuali osservate tra due variabili categoriche in un campione sono significative o solo dovute al rumore casuale nei dati. Nell'esempio precedente, gli 86% di primarie vinte da Clinton e Trump sono significativamente diversi dai 55% di primarie vinte da Sanders e Trump. I giornalisti dovrebbero sempre stare attenti a fare questi giudizi solo guardando le percentuali o i conteggi osservati, a causa della soggettività di tali decisioni. Le decisioni soggettive possono essere ulteriormente offuscate da nozioni preconcette sulle questioni relative ai dati.
Kolabtree helps businesses worldwide hire freelance scientists and industry experts on demand. Our freelancers have helped companies publish research papers, develop products, analyze data, and more. It only takes a minute to tell us what you need done and get quotes from experts for free.

Unlock Corporate Benefits
• Secure Payment Assistance
• Onboarding Support
• Dedicated Account Manager
Sign up with your professional email to avail special advances offered against purchase orders, seamless multi-channel payments, and extended support for agreements.


