



Cet article est rédigé par Paul Ricciun expert de Kolabtree. Il a été publié à l'origine dans sa chronique sur Le journalisme basé sur les données.
Cet article explique comment le test exact de Fisher peut être utilisé pour les tableaux de contingence de petits échantillons. Un problème courant en analyse des données est de savoir comment déterminer s'il existe une relation statistique entre deux variables catégorielles telles que le sexe, la race ou la part des votes pour deux candidats lors d'une élection. La façon la plus simple de visualiser la relation est de représenter les comptes pour chaque combinaison de deux variables dans un tableau de contingence dont les lignes représentent les niveaux d'une variable et les colonnes les niveaux de l'autre variable. Le test statistique le plus couramment utilisé pour détecter une association entre les variables des lignes et des colonnes est le test du chi carré (χ2). L'exemple du tableau ci-dessous est donné pour illustrer le test.
| Gagnant démocrate (% de la colonne) | Total | ||
| Victoire de Clinton | La victoire de Sanders | ||
| Trump 1er | 25 (86%) | 12 (55%) | 37 |
| Trump 2ème | 3 (11%) | 8 (36%) | 11 |
| Trump 3ème | 1 (3%) | 2 (9%) | 3 |
| Total | 29 (100%) | 22 (100%) | 51 |
Les colonnes du tableau ci-dessus indiquent les états primaires remportés par Hillary Clinton et par Bernie Sanders du côté démocrate et ceux remportés par Donald Trump dans les mêmes états primaires du côté républicain. Le nombre total d'États dans le tableau est de 51 car le district de Columbia est inclus. Les pourcentages en colonne montrent que Trump a remporté 86% des États primaires remportés par Clinton et 55% des États remportés par Sanders.
Le test du chi-deux est basé sur le calcul des valeurs attendues pour chaque cellule du tableau. Par exemple, la valeur attendue (la valeur de la cellule que l'on s'attendrait à voir s'il n'y avait pas de relation entre les variables) pour la cellule des États où Trump a terminé troisième du côté républicain et des États où Bernie Sanders a gagné du côté démocrate serait calculée en multipliant le total de la ligne pour les États où Trump a terminé troisième (3) par le total de la colonne pour les États où Sanders a gagné (22). Ce produit est ensuite divisé par le nombre total d'observations pour (51). La formule de la valeur attendue est donnée par :
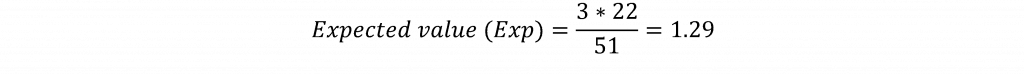
Cela signifie que pour cette cellule, une valeur de 1,29 serait attendue si les États primaires où Trump a terminé troisième et Sanders a gagné étaient complètement indépendants les uns des autres. La valeur observée pour cette cellule est de 2, ce qui suggère un nombre plus élevé que prévu pour cette cellule. Les valeurs attendues sont calculées pour chaque cellule du tableau et la différence entre les valeurs observées et attendues pour chaque cellule est calculée, élevée au carré, divisée par la valeur attendue et additionnée à toutes les cellules du tableau selon la formule :
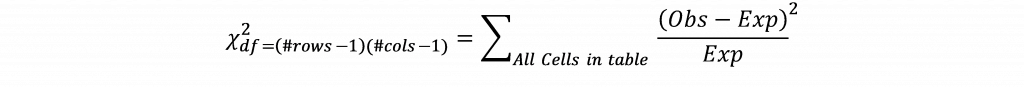
Si la valeur du khi-carré dépasse la valeur critique du khi-carré pour un degré de liberté donné (obtenu en multipliant le nombre de lignes moins un et le nombre de colonnes moins un) et la valeur p, on conclut qu'il existe une association entre les variables.
Il y a un problème avec le test du chi-deux. Il s'agit d'une approximation de la distribution des effectifs dans les tableaux de contingence. Si plus de 20% des cellules du tableau ont une valeur attendue inférieure à cinq, l'approximation du chi carré ne fonctionne pas pour tester l'hypothèse d'une association entre la variable de ligne et la variable de colonne (comme c'est le cas dans le tableau ci-dessous). Les deux variables du tableau sont catégoriques. Les principaux progiciels statistiques alertent l'utilisateur si cette hypothèse est violée. La violation de cette hypothèse entraîne une valeur p incorrecte et peut conduire à des conclusions erronées concernant la présence ou l'absence d'une association. Il existe une alternative exacte au test du chi-deux, appelée test exact de Fisher.
Le test exact de Fisher est basé sur la distribution de probabilité hypergéométrique.
![]()
Ici, le Ri! sont les factorielles des totaux des lignes (5!=5*4*3*2*1), Ci! sont les factorielles des totaux des colonnes individuelles, N ! est la factorielle du total du tableau et l'aij! sont les factorielles pour les valeurs des cellules individuelles. Les valeurs Πij est le coefficient du produit des valeurs des cellules individuelles. Une telle formule est encore plus gourmande en ressources informatiques que le test du chi-deux, en particulier pour les tableaux comportant de nombreuses lignes et colonnes. C'est la raison pour laquelle le test du chi-deux était privilégié dans le passé, car il nécessitait trop de mémoire pour être exécuté par les ordinateurs. Aujourd'hui, le test exact de Fisher pose moins de problèmes aux ordinateurs et il est facile à exécuter dans les principaux progiciels statistiques (R, SAS, SPSS), STATAetc.).
Les commandes permettant de réaliser le test exact de Fisher et le test du chi-deux en R (un programme gratuit) sont présentées ci-dessous pour le tableau figurant en haut de l'article, avec les résultats correspondants (en jaune pour le test exact de Fisher, en vert pour le test du chi-deux).
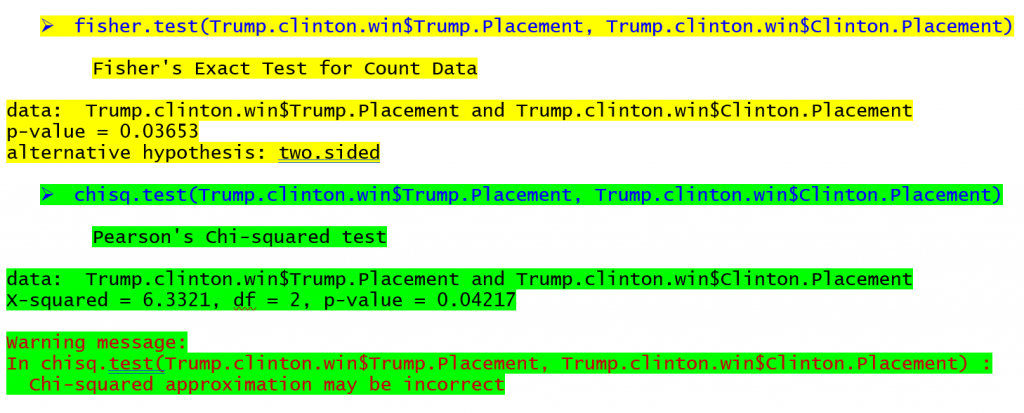
Le résultat du test exact de Fisher montre qu'il existe une probabilité de 0,03653 d'observer ces fréquences de tableau lorsqu'il n'y a pas d'association entre les lignes et les colonnes. Le résultat du test du chi-deux montre une probabilité de 0,04217 pour une relation dans le même tableau. Si nous utilisions la valeur p de 0,05 comme critère de signification, nous trouverions une relation pour les deux tests dans ce cas, bien que les valeurs p soient différentes. Les États remportés par Hillary Clinton pendant la saison des primaires étaient plus susceptibles d'être remportés par Donald Trump, tandis que les États remportés par Bernie Sanders étaient plus susceptibles de voir Trump terminer à la deuxième place.et ou 3rd Dans les tableaux où la taille des échantillons est encore plus réduite, la différence entre les valeurs p peut être encore plus grande, ce qui conduit à des conclusions radicalement différentes.
A titre d'avertissement, la valeur p ne doit pas être utilisée comme un indicateur de la force de l'association entre des variables catégorielles. Soit le test est significatif, soit il ne l'est pas. La valeur p est sensible à la taille de l'échantillon. On utilise souvent l'odds ratio pour estimer la taille de l'effet, mais R ne le calcule que dans la fonction fisher.test pour les tableaux à 2 colonnes et 2 lignes.
Le test exact de Fisher fournit un critère permettant de décider si les différences de pourcentages observées entre deux variables catégorielles dans un échantillon sont significatives ou simplement dues à un bruit aléatoire dans les données. Dans l'exemple ci-dessus, les 86% des primaires remportées par Clinton et Trump sont significativement différentes des 55% des primaires remportées par Sanders et Trump. Les journalistes doivent toujours être prudents avant de porter ces jugements en se contentant d'observer les pourcentages ou les décomptes, en raison de la subjectivité de ces décisions. Les décisions subjectives peuvent encore être obscurcies par des notions préconçues sur les questions liées aux données.
Kolabtree helps businesses worldwide hire freelance scientists and industry experts on demand. Our freelancers have helped companies publish research papers, develop products, analyze data, and more. It only takes a minute to tell us what you need done and get quotes from experts for free.

Unlock Corporate Benefits
• Secure Payment Assistance
• Onboarding Support
• Dedicated Account Manager
Sign up with your professional email to avail special advances offered against purchase orders, seamless multi-channel payments, and extended support for agreements.


