



Este artículo apareció originalmente en mi columna en el sitio periodismo basado en datos.
En mi En el último post hablé de cómo la regresión puede ser una herramienta útil para separar las diferentes relaciones entre las variables correlacionales. También hablé de cómo los valores atípicos pueden ser problemáticos. Una forma de tratar un valor atípico es simplemente eliminarlo del análisis. Hacerlo disminuye la potencia estadística (la probabilidad de encontrar un predictor significativo cuando existe) y elimina información potencialmente valiosa del modelo. Podría ser un esfuerzo más fructífero, ya que se puede obtener información valiosa. Hice esto en mi post sobre cómo Washington, DC se diferencia de los otros estados y me dio una idea para otra covariable que debería ser considerada además de las ya consideradas: concentración de grupos de odio, % sin seguro, % con licenciatura o superior y % en la pobreza.
En mi post sobre las características de Washington, DC como ciudad atípica Descubrí que es el menos blanco en comparación con cualquiera de los estados considerados. Sólo el 40,2% de la población de los distritos se identifica como blanca o caucásica allí. Sólo Hawái tiene un % de blancos menor, con un 25,4%. En la encuesta a pie de urna de las elecciones del año pasado, 60% de las mujeres blancas sin estudios universitarios votaron por Trump, mientras que 71% de los hombres blancos sin estudios universitarios lo hicieron. 74% de los no blancos votaron por Clinton.
Añadir esto al modelo mejoró significativamente la precisión del modelo con DC incluido con el 78,5% de la variabilidad del voto de Trump contabilizado. Las variables de grupos de odio y % pobreza no fueron significativas y se excluyeron ya que tenerlas en el modelo disminuye la potencia estadística. Las variables % licenciatura, % blanco y % sin seguro fueron significativas (lo que significa que el valor p es inferior a 0,05 lo explicaré en un futuro post), las demás no lo fueron. El resultado de la mayoría de los paquetes estadísticos:
|
78,5% de la variabilidad contabilizado |
Coeficientes |
Error estándar |
t Declaración |
Valor P |
Baja 95% |
Arriba 95% |
|
Interceptar |
51.55 |
8.92 |
5.78 |
5.75E-07 |
33.61 |
69.48 |
|
% licenciatura o superior |
-1.11 |
0.15 |
-7.55 |
1.2E-09 |
-1.41 |
-0.82 |
|
% Blanco |
0.31 |
0.06 |
4.95 |
1.01E-05 |
0.18 |
0.43 |
|
% no asegurado |
0.74 |
0.26 |
2.86 |
0.006319 |
0.22 |
1.26 |
La columna titulada "coeficientes" da los valores estimados para la ecuación de regresión que expliqué en entradas anteriores. La ecuación actual se lee:
Trump % de los votos = 51,55 - 1,11*(% licenciados) + 0,31*(% blancos) + 0,74*(% no asegurados)
Esto dice que cuando todas las covariables son iguales a cero, se predice que Trump tendrá 51,55% de los votos. Por cada aumento de 1% en la población blanca de % se estima una disminución de 1,11% en el voto de Trump. Por cada aumento de 1% en la población blanca de % en el estado hay un aumento estimado de 0,31% y por cada aumento de 1% en la población sin seguro en el estado.
La columna denominada "error estándar" es una estimación de la incertidumbre de los coeficientes. La columna denominada "t stat" es el estadístico de prueba para determinar si los coeficientes son significativamente diferentes de cero. El "valor p" es la probabilidad estimada de observar este coeficiente estimado cuando el coeficiente verdadero es cero. Por convención, cuando el valor p es inferior a 0,05 se concluye que el coeficiente verdadero es diferente de cero. Las dos últimas columnas muestran los límites superior e inferior de un intervalo de confianza de 95% para un coeficiente. El intervalo de confianza dice que el 95% de las veces que se hacen las estimaciones, el coeficiente verdadero estará entre los límites superior e inferior. En este caso, si los límites superior e inferior no están a caballo entre el número cero, eso equivale a que el coeficiente es significativamente diferente de cero.
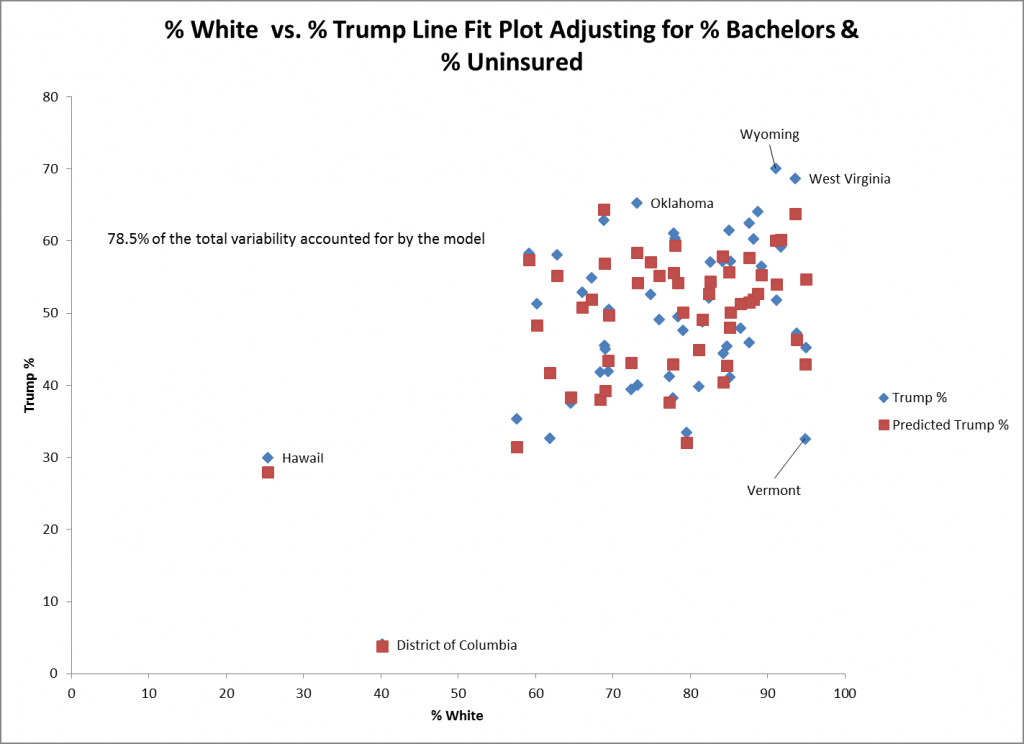
El diagrama de dispersión anterior muestra los valores reales (en el rombo azul) y los previstos (en los cuadrados rojos) para % blanco y % Trump para el modelo que se ajusta por % soltero y % sin seguro. Los valores reales y predichos para el Distrito de Columbia (DC) y Hawái están muy próximos entre sí, lo que sugiere un buen ajuste. Un estado que se ajusta mal es Vermont, donde el voto real a Trump es 10% inferior al voto previsto, lo que puede verse directamente encima del diamante azul de Vermont.
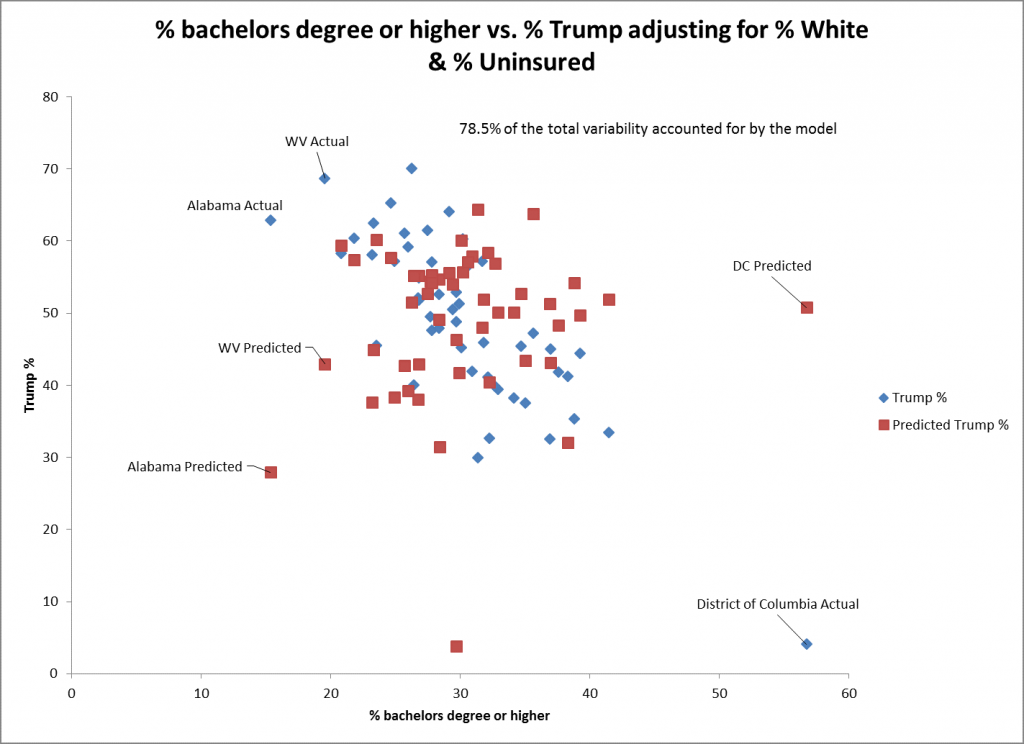
El gráfico de dispersión para % licenciatura o superior sugiere que el ajuste no es tan bueno como el de % blanco como predictor. Esto se refleja en el mayor error estándar de este predictor (0,15) que el de % blanco (0,06). La predicción para DC no es tan buena para este predictor, ya que tiene el más alto. La tendencia sigue siendo significativa en la dirección negativa.
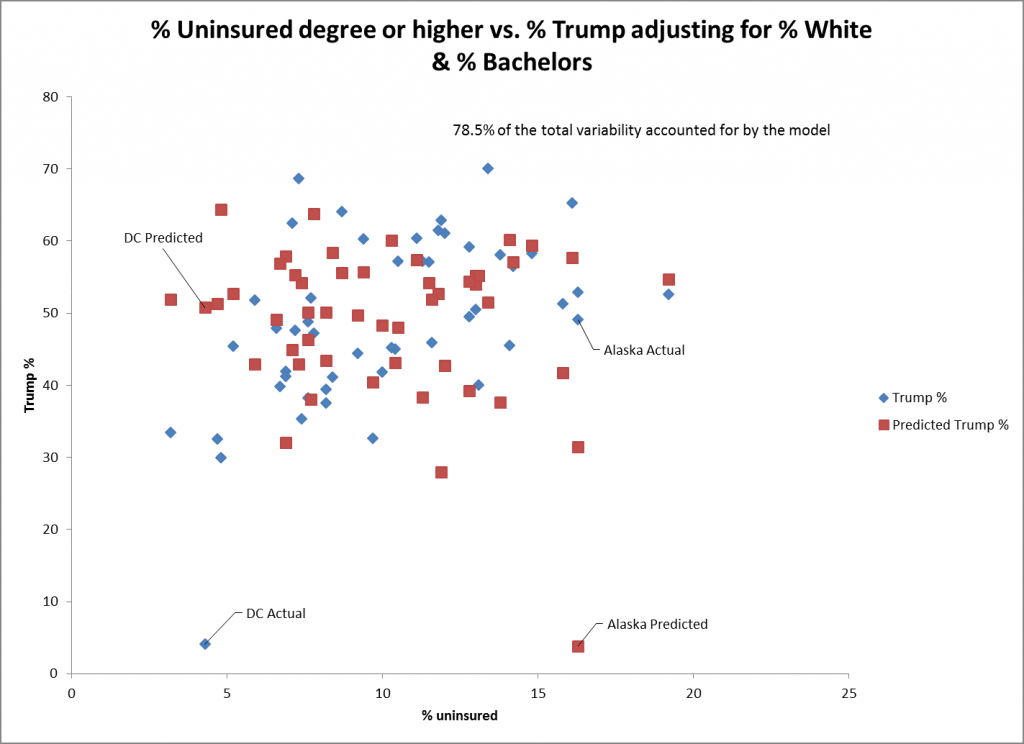
El diagrama de dispersión para el % de no asegurados como predictor muestra un ajuste aún menor para el % de votos de Trump. DC y Alaska son puntos de mal ajuste para este predictor entre muchos otros estados. El error estándar de este predictor muestra un ajuste aún menor (0,26) que el de los otros predictores, aunque sigue siendo estadísticamente significativo.
La regresión múltiple es una herramienta potencialmente poderosa para desentrañar las relaciones entre las variables predictoras de un resultado específico cuando se realiza correctamente. Añadir las covariables adecuadas, como la raza, puede ayudar a paliar los efectos de un valor atípico como el de Washington DC. Siempre es mejor incluir todos los datos para obtener la imagen más completa posible.
Ahora vemos que a medida que aumenta el % de la población de un estado con una licenciatura o superior disminuye el % del voto a Trump. Al mismo tiempo, a medida que aumentan los porcentajes de blancos y de no asegurados en un estado, aumenta el % del voto a Trump. En presencia de estas variables la concentración de grupos de odio y el % del estado en pobreza dejan de ser predictores significativos del voto a Trump.
Mientras Trump y el congreso controlado por los republicanos se preparan para derogar la Ley de Cuidado de Salud Asequible (ACA o como dice el GOP Obamacare), la Oficina de Presupuesto del Congreso estima que 23 millones de estadounidenses perderán su seguro de salud en la versión de la Cámara de Representantes y se estima que 22 millones lo perderán en la versión del Senado. En este modelo, la tasa de no asegurados en cada estado está positivamente correlacionada con el voto de Trump. ¿Cree Trump que el aumento de la tasa de no asegurados aumentará su porcentaje de votos en 2020?
La pobreza no se asoció al voto de Trump en 2016. La disminución de las estimaciones de no asegurados desde que la ACA entró en vigor en 2014 se debe principalmente a la expansión de Medicaid para las personas más pobres y a los subsidios que permiten a las personas de menores ingresos adquirir un seguro médico. El aumento del número de no asegurados puede no disminuir el voto de Trump, pero es poco probable que lo aumente.
Kolabtree helps businesses worldwide hire freelance scientists and industry experts on demand. Our freelancers have helped companies publish research papers, develop products, analyze data, and more. It only takes a minute to tell us what you need done and get quotes from experts for free.

Unlock Corporate Benefits
• Secure Payment Assistance
• Onboarding Support
• Dedicated Account Manager
Sign up with your professional email to avail special advances offered against purchase orders, seamless multi-channel payments, and extended support for agreements.


