



Este posto é de autoria de Paul Riccium especialista em Kolabtree. Apareceu originalmente em sua coluna sobre Jornalismo com base em dados.
Este artigo descreve como o teste exato da Fisher pode ser usado para pequenas tabelas de contingência de amostras. Um problema comum em análise de dados é como determinar se existe uma relação estatística entre duas variáveis categóricas como sexo, raça, ou a proporção do voto para dois candidatos em uma eleição. A maneira mais simples de visualizar a relação é representar as contagens para cada combinação de duas variáveis em uma tabela de contingência com as linhas representando os níveis de uma variável e as colunas representando os níveis da outra variável. O teste estatístico mais comumente utilizado para uma associação entre as variáveis de linha e coluna é o qui-quadrado (χ2) teste. O exemplo na tabela abaixo é dado para ilustrar o teste.
| Vencedor democrata (% da coluna) | Total | ||
| Clinton Win | Sanders ganham | ||
| Trunfo 1o. | 25 (86%) | 12 (55%) | 37 |
| Trump 2o. | 3 (11%) | 8 (36%) | 11 |
| Trunfo 3o. | 1 (3%) | 2 (9%) | 3 |
| Total | 29 (100%) | 22 (100%) | 51 |
As colunas na tabela acima mostram os estados primários ganhos por Hillary Clinton e por Bernie Sanders do lado democrata e Donald Trump colocados nos mesmos estados primários do lado republicano. O número total de estados na tabela é 51 porque o Distrito de Columbia está incluído. Os percentuais da coluna mostram que Trump ganhou 86% dos estados primários que Clinton ganhou enquanto ele ganhou 55% dos estados que Sanders ganhou.
O teste do qui-quadrado é baseado no cálculo dos valores esperados para cada célula da tabela. Por exemplo, o valor esperado (o valor para a célula que se esperaria ver se não houvesse relação entre as variáveis) para a célula para estados onde Trump terminou em terceiro lugar no lado Republicano e para estados onde Bernie Sanders ganhou no lado Democrata seria computado multiplicando-se o total da linha para onde Trump terminou em terceiro lugar (3) pelo total da coluna para estados onde Sanders ganhou (22). Este produto é então dividido pelo número total de observações para (51). A fórmula para o valor esperado é dada por:
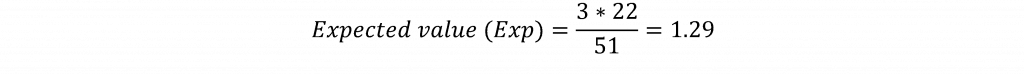
Isso significa que para esta célula seria esperado um valor de 1,29 se os estados primários onde Trump terminou em terceiro lugar e Sanders ganhou fossem completamente independentes um do outro. O valor observado para esta célula é 2, o que sugere uma contagem maior para esta célula do que seria esperado. Os valores esperados seriam calculados para cada célula da tabela e a diferença entre os valores observados e esperados para cada célula é calculada, ao quadrado, dividida pelo valor esperado, e somada entre as células da tabela de acordo com a fórmula:
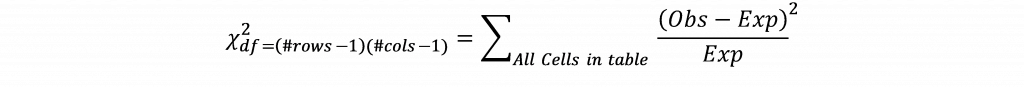
Se o valor do qui-quadrado exceder o valor crítico do qui-quadrado para um determinado grau de liberdade (encontrado multiplicando o número de linhas menos uma e o número de colunas menos uma) e p-valor, conclui-se que existe uma associação entre as variáveis.
Há um problema com o teste do qui-quadrado. É uma aproximação da distribuição das contagens nas tabelas de contingência. Se mais de 20% das células da tabela tiverem um valor esperado inferior a cinco, a aproximação qui-quadrado não funciona para testar a hipótese de uma associação entre a variável de linha e a variável de coluna (como é o caso na tabela abaixo). Ambas as variáveis na tabela são categóricas. Os principais pacotes estatísticos alertarão o usuário se esta suposição for violada. A violação da suposição faz com que o valor p observado seja incorreto e pode levar a conclusões incorretas em relação à presença ou ausência de uma associação. Existe uma alternativa exata para o teste qui-quadrado chamada teste exato de Fisher.
O teste exato da Fisher é baseado na distribuição de probabilidade hipergeométrica.
![]()
Aqui o Ri! são os fatores dos totais de linha (5!=5*4*3*2*1), Ci! são os fatores dos totais das colunas individuais, N! é o fatorial do total da tabela e o aij! são os fatores para os valores individuais das células. O Πij é o coeficiente do produto dos valores individuais das células. Tal fórmula é ainda mais intensiva em termos computacionais do que o teste do qui-quadrado, especialmente para tabelas com muitas linhas e colunas. É por isso que o teste de qui-quadrado foi favorecido no passado, pois era preciso muita memória para que os computadores funcionassem. Atualmente, é menos problemático para os computadores executarem o teste exato do Fisher e é fácil de executar nos principais pacotes estatísticos (R, SAS, SPSS, STATAetc.).
Os comandos para conduzir o teste exato de Fisher e o teste do qui-quadrado em R (um programa gratuito) podem ser vistos abaixo para a tabela no topo do artigo com a saída correspondente (amarelo para o teste exato de Fisher, verde para o teste do qui-quadrado).
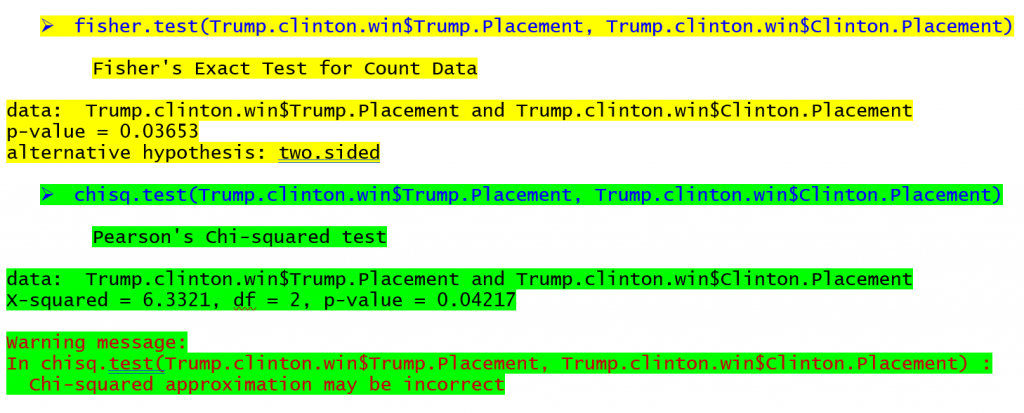
A saída para o teste exato do Fisher mostra que há uma probabilidade de 0,03653 de observar essas freqüências de tabela quando não há associação entre as linhas e as colunas. A saída do teste do qui-quadrado mostra uma probabilidade de 0,04217 para uma relação na mesma tabela. Se estivéssemos usando o valor 0,05 p como critério de significância, encontraríamos uma relação para ambos os testes neste caso, embora os valores de p sejam diferentes. Os estados que Hillary Clinton venceu na temporada primária tinham mais probabilidade de ser vencidos por Donald Trump enquanto os estados onde Bernie Sanders venceu tinham mais probabilidade de ter Trump 2nd ou 3rd Em tabelas com amostras ainda menores, a diferença entre os valores p pode ser ainda maior, levando a conclusões radicalmente diferentes.
Como um aviso, o valor p não deve ser usado como um indicador da força da associação entre as variáveis categóricas. Ou o teste é significativo ou não. O valor de p é sensível ao tamanho da amostra. Muitas vezes a razão de probabilidade é usada para estimar o tamanho do efeito, mas R apenas o calcula na função de teste de pescador para tabelas com 2 colunas e 2 fileiras.
O teste exato de Fisher fornece um critério para decidir se as diferenças nas porcentagens observadas entre duas variáveis categóricas em uma amostra são significativas ou apenas devido ao ruído aleatório nos dados. No exemplo acima, o 86% dos estados primários ganhos por Clinton e Trump são significativamente diferentes do 55% dos primários ganhos por Sanders e Trump. Os jornalistas devem sempre ser cuidadosos ao fazer estes julgamentos apenas observando as porcentagens ou contagens observadas, devido à subjetividade de tais decisões. As decisões subjetivas podem ser ainda mais obscurecidas por noções pré-concebidas sobre as questões relacionadas aos dados.
Kolabtree helps businesses worldwide hire freelance scientists and industry experts on demand. Our freelancers have helped companies publish research papers, develop products, analyze data, and more. It only takes a minute to tell us what you need done and get quotes from experts for free.

Unlock Corporate Benefits
• Secure Payment Assistance
• Onboarding Support
• Dedicated Account Manager
Sign up with your professional email to avail special advances offered against purchase orders, seamless multi-channel payments, and extended support for agreements.


