



Este artículo ha sido escrito por Paul Ricciun experto en Kolabtree. Apareció originalmente en su columna en Periodismo basado en datos.
Este artículo describe cómo puede utilizarse la prueba exacta de Fisher para las tablas de contingencia de muestras pequeñas. Un problema común en análisis de datos es cómo determinar si existe una relación estadística entre dos variables categóricas, como el sexo, la raza o el porcentaje de votos de dos candidatos en unas elecciones. La forma más sencilla de visualizar la relación es representar los recuentos de cada combinación de dos variables en una tabla de contingencia en la que las filas representan los niveles de una variable y las columnas los niveles de la otra. La prueba estadística más utilizada para detectar una asociación entre las variables de las filas y de las columnas es el chi-cuadrado (χ2). El ejemplo de la tabla siguiente se ofrece para ilustrar la prueba.
| Ganador demócrata (% de la columna) | Total | ||
| Victoria de Clinton | Victoria de Sanders | ||
| Trump 1er. | 25 (86%) | 12 (55%) | 37 |
| Trump 2º | 3 (11%) | 8 (36%) | 11 |
| Trump 3º | 1 (3%) | 2 (9%) | 3 |
| Total | 29 (100%) | 22 (100%) | 51 |
Las columnas de la tabla anterior muestran los estados de las primarias ganados por Hillary Clinton y por Bernie Sanders en el lado demócrata y los puestos de Donald Trump en los mismos estados de las primarias en el lado republicano. El número total de estados en la tabla es de 51 porque se incluye el Distrito de Columbia. Los porcentajes de las columnas muestran que Trump ganó 86% de los estados de las primarias que ganó Clinton mientras que ganó 55% de los estados que ganó Sanders.
La prueba de chi-cuadrado se basa en el cálculo de los valores esperados para cada celda de la tabla. Por ejemplo, el valor esperado (el valor de la celda que se esperaría ver si no hubiera ninguna relación entre las variables) para la celda de los estados en los que Trump quedó en tercer lugar en el lado republicano y para los estados en los que Bernie Sanders ganó en el lado demócrata se calcularía multiplicando el total de la fila en la que Trump quedó en tercer lugar (3) por el total de la columna de los estados en los que ganó Sanders (22). Este producto se divide por el número total de observaciones (51). La fórmula para el valor esperado viene dada por:
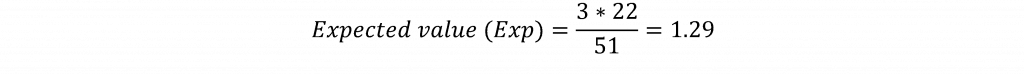
Esto significa que para esta celda se esperaría un valor de 1,29 si los estados de las primarias en los que Trump terminó tercero y Sanders ganó fueran completamente independientes entre sí. El valor observado para esta celda es 2, lo que sugiere un recuento más alto para esta celda de lo que se esperaría. Los valores esperados se calcularían para cada celda de la tabla y la diferencia entre los valores observados y los esperados para cada celda se calcula, se eleva al cuadrado, se divide por el valor esperado y se suma en todas las celdas de la tabla según la fórmula:
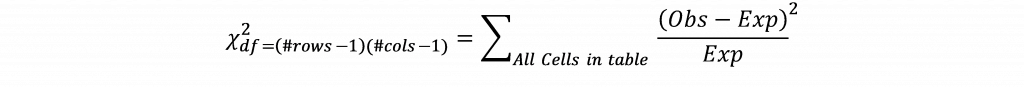
Si el valor de la chi-cuadrado supera el valor crítico de la chi-cuadrado para un grado de libertad determinado (que se obtiene multiplicando el número de filas menos uno y el número de columnas menos uno) y el valor p, se concluye que existe una asociación entre las variables.
Hay un problema con la prueba de chi-cuadrado. Es una aproximación a la distribución de los recuentos en las tablas de contingencia. Si más de 20% de las celdas de la tabla tienen un valor esperado inferior a cinco, la aproximación chi-cuadrado no funciona para probar la hipótesis de una asociación entre la variable de la fila y la variable de la columna (como ocurre en la tabla siguiente). Las dos variables de la tabla son categóricas. Los principales paquetes estadísticos alertan al usuario si se viola esta suposición. La violación del supuesto hace que el valor p observado sea incorrecto y puede llevar a conclusiones incorrectas sobre la presencia o ausencia de una asociación. Existe una alternativa exacta a la prueba de chi-cuadrado denominada prueba exacta de Fisher.
La prueba exacta de Fisher se basa en la distribución de probabilidad hipergeométrica.
![]()
Aquí el Ri! son los factoriales de los totales de las filas (¡5!=5*4*3*2*1), Ci! son los factoriales de los totales de las columnas individuales, ¡N! es el factorial del total de la tabla y el aij! son los factoriales para los valores individuales de las celdas. Los Πij es el coeficiente del producto de los valores individuales de las celdas. Esta fórmula es aún más intensiva desde el punto de vista computacional que la prueba de chi-cuadrado, especialmente para las tablas con muchas filas y columnas. Por este motivo, en el pasado se prefería la prueba de chi-cuadrado, ya que los ordenadores necesitaban demasiada memoria para ejecutarla. Hoy en día es menos problemático para los ordenadores ejecutar la prueba exacta de Fisher y es fácil de ejecutar en los principales paquetes estadísticos (R, SAS, SPSS, STATAetc.).
Los comandos para llevar a cabo la prueba exacta de Fisher y la prueba de chi-cuadrado en R (un programa gratuito) se pueden ver a continuación para la tabla en la parte superior del artículo con la salida correspondiente (amarillo para la prueba exacta de Fisher, verde para la prueba de chi-cuadrado).
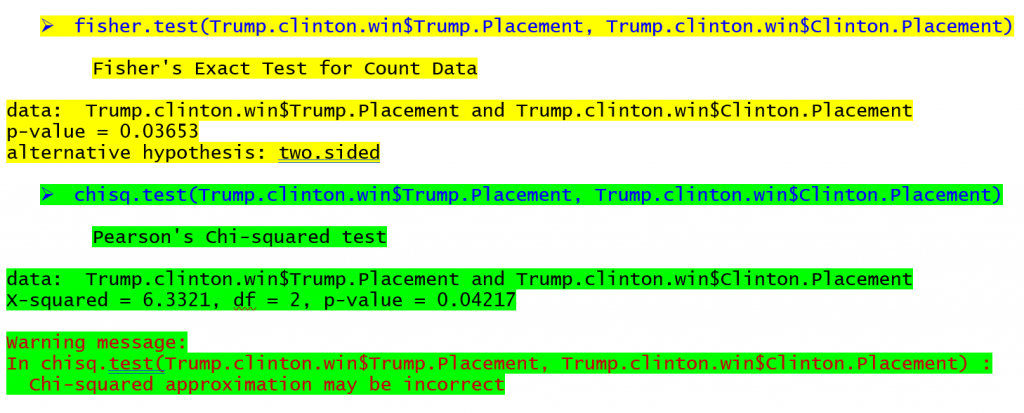
La salida de la prueba exacta de Fisher muestra que hay una probabilidad de 0,03653 de observar estas frecuencias de la tabla cuando no hay asociación entre las filas y las columnas. La salida de la prueba de chi-cuadrado muestra una probabilidad de 0,04217 para una relación en la misma tabla. Si utilizáramos el valor p de 0,05 como criterio de significación, encontraríamos una relación para ambas pruebas en este caso, aunque los valores p difieren. Los estados en los que ganó Hillary Clinton en las primarias tenían más probabilidades de que ganara Donald Trump, mientras que los estados en los que ganó Bernie Sanders tenían más probabilidades de que Trump terminara 2nd o 3rd En tablas con tamaños de muestra aún más pequeños, la diferencia entre los valores p puede ser aún mayor, lo que lleva a conclusiones radicalmente diferentes.
Como advertencia, el valor p no debe utilizarse como indicador de la fuerza de la asociación entre variables categóricas. La prueba es significativa o no. El valor p es sensible al tamaño de la muestra. A menudo se utiliza el odds ratio para estimar el tamaño del efecto, pero R sólo lo calcula en la función fisher.test para tablas con 2 columnas y 2 filas.
La prueba exacta de Fisher proporciona un criterio para decidir si las diferencias en los porcentajes observados entre dos variables categóricas en una muestra son significativas o sólo se deben al ruido aleatorio de los datos. En el ejemplo anterior, los 86% de las primarias ganadas por Clinton y Trump son significativamente diferentes de los 55% de las primarias ganadas por Sanders y Trump. Los periodistas siempre deben tener cuidado al hacer estos juicios sólo mirando los porcentajes o recuentos observados debido a la subjetividad de tales decisiones. Las decisiones subjetivas pueden verse aún más empañadas por las nociones preconcebidas sobre los temas relacionados con los datos.
Kolabtree helps businesses worldwide hire freelance scientists and industry experts on demand. Our freelancers have helped companies publish research papers, develop products, analyze data, and more. It only takes a minute to tell us what you need done and get quotes from experts for free.

Unlock Corporate Benefits
• Secure Payment Assistance
• Onboarding Support
• Dedicated Account Manager
Sign up with your professional email to avail special advances offered against purchase orders, seamless multi-channel payments, and extended support for agreements.


